- Diseño y desarrollo de un entorno de fotogrametría con drones asistido por IA
- Aplicación Android para fotogrametría con IA. Verificación del entorno y Fase 1 de desarrollo inicial
- Aplicación Android para fotogrametría con IA. Fase 2: Primera versión capaz de volar
- Aplicación Android para fotogrametría con IA. Fase 3: Corrección de heading, visualización en vuelo y ajustes de UX
- Aplicación Android para fotogrametría con IA. La plataforma de procesado: OpenDroneMap desplegado con Claude Code
- Aplicación Android para fotogrametría con IA. Fase 4: Integración cloud, exportación KMZ y cierre del ciclo completo
- Fotogrametría con IA: Detección de hallazgos en tiempo real durante el vuelo. Módulo de auditoría IA con YOLOv8 y RTMP sobre el stack ODM
- Aplicación Android para fotogrametría con IA. Fase 5: Streaming RTMP y telemetría en tiempo real — cómo se coordina un sistema entre dos agentes de IA
- Aplicación Android para fotogrametría con IA. Fase 6: Resultados en el mapa, gestión multi-batería y reanudación de misiones
- Aplicación Android para fotogrametría con IA. Fase 7: Edición de polígono, estimación de batería corregida y caché offline
- Aplicación Android para fotogrametría con IA. Fase 8: Condiciones de vuelo — meteorología AEMET, índice Kp y GPS en tiempo real
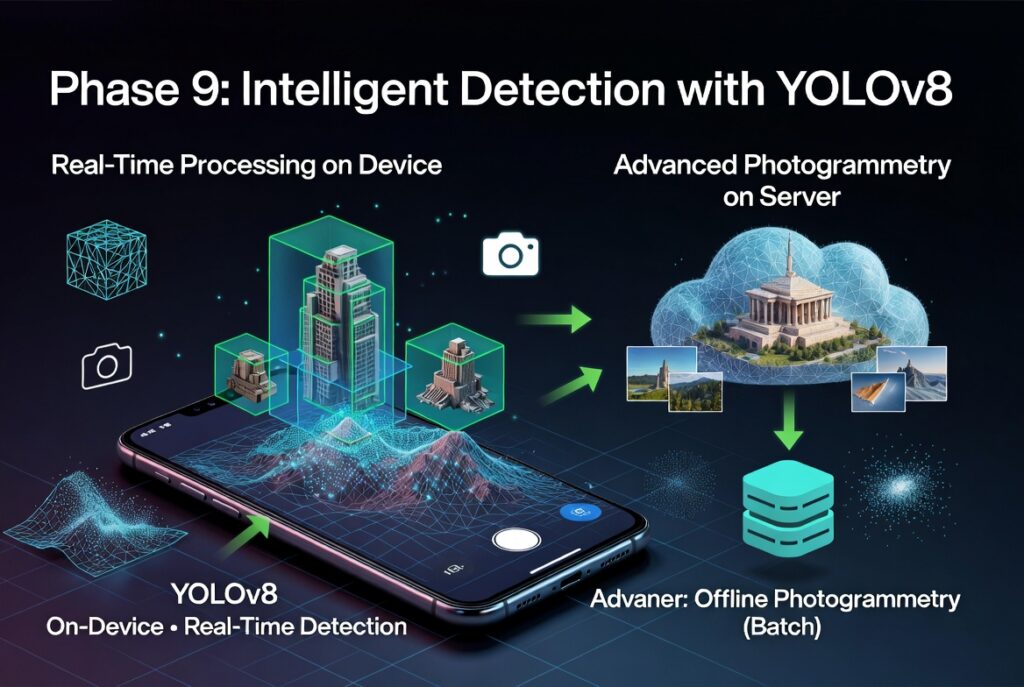
- Aplicación Android para fotogrametría con IA. Fase 9: Detección inteligente de objetos a dos niveles, dispositivo y servidor
- Fotogrametría asistida con IA: Pruebas de campo. Cuando el firmware no hace lo que promete
La Fase 8 dejó cerrado el panel de condiciones de vuelo: meteorología de AEMET, índice geomagnético Kp de la NOAA y monitorización GPS en tiempo real. Con toda esa información, el piloto sabe si es buen momento para volar. Pero una vez en el aire, ¿qué ve el dron? Hasta ahora, la única respuesta llegaba con retraso: el módulo de auditoría del servidor procesaba el stream RTMP con un YOLOv8n genérico y, francamente, los resultados dejaban bastante que desear: en un vuelo de validación del proceso de cuatro minutos se realizaron 105 detecciones, la mayoría falsos positivos. La Fase 9 nace para resolver exactamente eso: darle ojos inteligentes al sistema, tanto en el aire como en tierra.
La idea inicial: Roboflow
Mi primera intuición fue hacer uso de Roboflow. Podía desplegar un MCP integrado en Claude Code para tener este entorno habilitado en el flujo de desarrollo asistido por IA, y la plataforma promete un pipeline completo: anotación, entrenamiento y despliegue. Pero creo que es conveniente dar un pequeño paso atrás, y explicar lo que es un MCP.
Un MCP, o Model Context Protocol, es un modelo de integración que permite que un agente de inteligencia artificial, como Claude Code, se conecte con herramientas externas para interactuar directamente con ellas, dentro de su propio flujo de trabajo, sin necesitar interacciones manuales entre distintos sistemas por parte del usuario, lo que incrementa de manera dramática las capacidades del agente de IA, ya que no sólo puede pedir al usuario que haga tal o cual tarea en el sistema externo, sino que puede usarlo directamente, e incluso evaluar el resultado de esa interacción. Sencillamente soberbio. Sus principales ventajas son las siguientes:
- Interoperabilidad Total: Las integraciones eran silos cerrados para pasar a ser esquemas interoperables. Un servidor MCP escrito para una base de datos de Postgres funciona igual de bien en Claude Desktop, en Claude Code o en cualquier otro IDE que adopte el estándar. No hay que reinventar la rueda.
- Contexto en Tiempo Real: En lugar de copiar y pegar logs o fragmentos de código, el MCP permite que la IA «pregunte» a la fuente de verdad en el momento exacto. Si el estado de un servidor cambia, Claude lo sabe porque tiene un canal directo de comunicación.
- Seguridad y Control Local:
- A diferencia de otras soluciones que requieren subir todos tus datos a la nube para que la IA los procese, los servidores MCP pueden ejecutarse localmente en tu máquina. Tú decides qué archivos o qué datos específicos permites que el modelo consulte, manteniendo la privacidad de la información sensible.

Volviendo a la mesa de dibujo, como decía, le pedí a Claude que evaluara la propuesta y, adicionalmente, incluí en el proceso de evaluación de la misma una validación del diseño preliminar contra ChatGPT, que precisamente tengo configurado como módulo de consulta desde Claude Code a través de su propio MCP. La razón de esto es poderlo utilizar como un «asesor externo» a Claude Code. Y en este caso, le pedí que hiciera la función de abogado del diablo.
El veredicto fue demoledor. Con el plan gratuito de Roboflow, la exportación a TFLite está bloqueada, los datos deben ser públicos, y las limitaciones de inferencia lo hacen inviable para un proyecto que aspira a funcionar en una combinación de procesamiento offline y en el propio dispositivo Android. ChatGPT, en su rol de adversario de razonamiento, identificó además que el acoplamiento a una plataforma comercial no tenía sentido para un proyecto personal sin ánimo de lucro inmediato. Punto para el abogado del diablo.
La alternativa: Ultralytics a coste cero
El plan B fue hacer uso, directamente, de Ultralytics. Las razones para ello eran de peso. En primer lugar, la licencia AGPL-3.0 lo hacen perfectamente válida para uso personal. En segundo lugar, el poder emplear YOLOv8n como arquitectura, en su configuración nano, de 6 MB, funciona perfectamente en CPU frente a GPU. Tercero, hace posible utilizar VisDrone como dataset de entrenamiento (se trata de 10.000 imágenes aéreas capturadas con drones DJI, lo que es exactamente mi dominio). Cuarto, la posibilidad de hacer entrenamiento gratuito en Google Colab o Kaggle con GPU T4. Y por último, la posibilidad de realizar exportación a todos los formatos que necesitaba: PyTorch para el servidor, TFLite INT8 para Android. Y todo ello a coste cero. Una aproximación muy completa para resolver el escenario que tenía encima de la mesa.
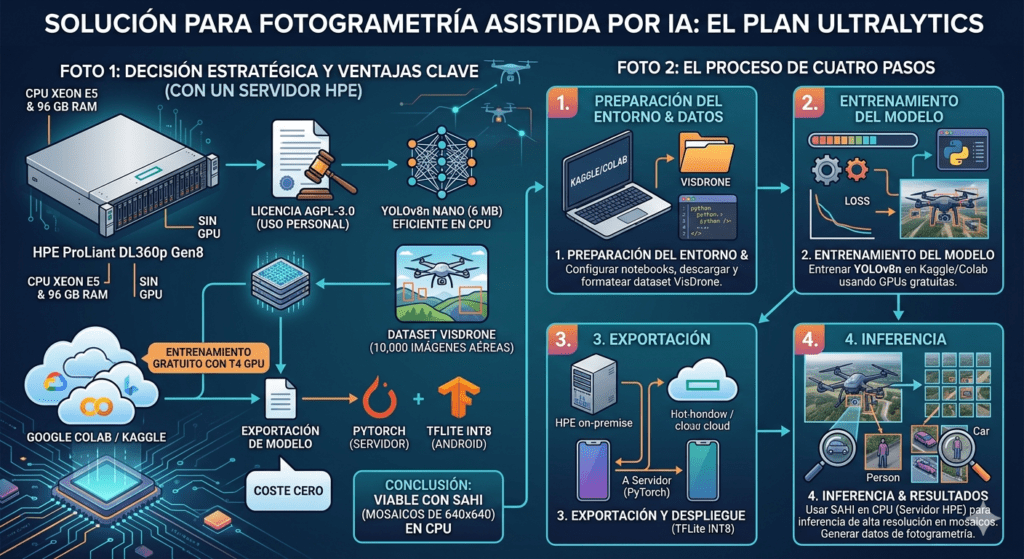
Aun así, antes de decidir, le pedí a Claude que usara el MCP de NotebookLM para hacer una investigación profunda sobre la viabilidad de usar Ultralytics en mi hardware (recordemos, un servidor HPE ProLiant DL360p Gen8 con Xeon E5 y 96 GB de RAM, pero sin GPU). La conclusión fue clara: para realizar inferencia en CPU sobre imágenes estáticas de alta resolución, el rendimiento era más que suficiente aplicando SAHI (Slicing Aided Hyper Inference) para dividir cada foto en mosaicos de 640×640. Ya sólo era cuestión de ponerse a ello, para lo que estructuré el proceso en cuatro pasos bien diferenciados.
Primer paso. Entrenamiento del modelo
La primera tarea fue entrenar un YOLOv8n especializado en vista aérea. El servidor ODM ya tenía un script de entrenamiento (train_visdrone.py) preparado desde la Fase 5, pero había fallado al intentar ejecutarlo en CPU. Tras varios intentos fallidos había acabado generando un core dump de 500 MB que confirmaba que entrenar en el Xeon no era viable.
Instalé el MCP oficial de Google Colab (googlecolab/colab-mcp) en el Mac Mini para controlar el notebook directamente desde Claude Code. La idea era elegante: crear celdas, ejecutarlas, leer resultados, todo sin salir del terminal. La realidad fue menos elegante.
Google Colab (o Colaboratory) es una plataforma gratuita basada en la nube que permite escribir y ejecutar código de Python directamente desde tu navegador, sin necesidad de realizar configuraciones previas en tu ordenador. Funciona bajo un sistema de «notebooks» (cuadernos interactivos) inspirados en Jupyter, donde puedes combinar texto enriquecido, ecuaciones matemáticas y código ejecutable, todo almacenado de forma automática en tu cuenta de Google Drive.
Lo que realmente lo distingue es el acceso gratuito a recursos de computación de alto rendimiento, específicamente GPUs y TPUs. Esto lo convierte en la herramienta muy valiosa para estudiantes, investigadores y desarrolladores de Inteligencia Artificial y Ciencia de Datos, ya que permite entrenar modelos complejos o procesar grandes volúmenes de información de manera rápida y colaborativa, tal como si estuvieras trabajando en un documento compartido de Google Docs. Sobre el papel era perfecto para esta fase de entrenamiento del modelo.
El primer intento llegó hasta la epoch 36 de 100 antes de que un MCP timeout cortara la conexión. Los checkpoints no se habían guardado porque el directorio de salida no estaba bien configurado. Al reintentar, el kernel de Colab se había reiniciado, perdiendo las dependencias instaladas y el dataset descargado. Vuelta a empezar.
El segundo intento añadía save_period=5 para guardar checkpoints cada 5 epochs. Llegó hasta la epoch 79 de 100 cuando Colab cortó la sesión por límite de uso de GPU gratuita. Y como los checkpoints estaban en almacenamiento efímero de Colab… se perdieron otra vez. Además, el MCP de Colab tenía un problema fundamental: update_cell reportaba éxito pero run_code_cell ejecutaba el contenido anterior de la celda. Las actualizaciones no sincronizaban con el runtime. Entre unas cosas y otras, fueron 6 horas de tiempo perdido.
El salto a Kaggle
Ya había identificado Kaggle como plataforma alternativa, y que aportaba las siguientes características: 30 horas semanales de GPU (más generoso que Colab), sesiones de hasta 12 horas, y /kaggle/working/ que persiste automáticamente tras finalizar la sesión. No hay MCP, pero a estas alturas eso era casi una ventaja, así que preparé un script completo en 6 celdas que el usuario ejecuta directamente en el navegador.
El primer obstáculo en Kaggle fue la existencia de un bug de la versión preinstalada de PyTorch (THPDtypeType.tp_dict == nullptr) que dio la cara al intentar ejecutar la primera de las celdas. Se resolvió instalando Ultralytics antes de importar torch, que trae su propia versión compatible. A partir de ahí, todo fue fluido: el entrenamiento completó 80 epochs en 2 horas y 7 minutos a 5.6 iteraciones por segundo.
Los resultados finales del entrenamiento fueron los siguientes:
| Clase | mAP@0.5 |
|---|---|
| car | 0.681 |
| bus | 0.321 |
| van | 0.254 |
| pedestrian | 0.249 |
| motor | 0.249 |
| Global | 0.236 |
El mAP global queda ligeramente por debajo del umbral de 0.25 que nos habíamos marcado, pero las clases relevantes para fotogrametría (coches, vehículos, peatones) tienen valores más que aceptables. Las clases que bajan la media — bicycle (0.029) y awning-tricycle (0.063) — son objetos muy pequeños y poco frecuentes que no son prioritarios para nuestro caso de uso.
Despliegue y comparativa con el modelo genérico
Con los modelos exportados (PyTorch de 5.9 MB y TFLite INT8 de 11.6 MB), el despliegue en el servidor fue directo: copiar el .pt a /odm-data/models/, actualizar la variable YOLO_MODEL en el docker-compose, y reiniciar el ai-processor.
La prueba de fuego fue volver a analizar el vídeo del vuelo real del 11 de abril con el nuevo modelo. El resultado fue contundente:
| Modelo | Detecciones | Observación |
|---|---|---|
| YOLOv8n genérico | 105 | Mayoría falsos positivos |
| YOLOv8n VisDrone | 9 | 5 peatones, 2 camiones, 2 autobuses |
De las 9 detecciones, la validación visual en el visor Leaflet confirmó que las 5 detecciones de peatón eran correctas (era yo, al inicio del vuelo), aunque aparecían duplicadas por detección en frames consecutivos. Un camión era un falso positivo, y dos detecciones de baja confianza (bus/peatón al 41%) correspondían en realidad a un árbol. Con tan sólo subir el umbral de confianza de 0.35 a 0.50, los falsos positivos desaparecieron y quedaron solo las detecciones válidas. Nada mal para una primera iteración, aunque aún espero mejorar mucho el proceso.
Segundo paso. Detección en tiempo real en el móvil
La segunda capa de detección se realiza en el dispositivo de captura: consiste en el mismo modelo YOLOv8n, pero cuantizado a TFLite INT8 y ejecutándose directamente en el teléfono durante el vuelo. Se trata de una duramente informativa: no controla el dron, sólo muestra al operador lo que el modelo ve.
La implementación requirió cuatro ficheros nuevos y tres modificados. El ObjectDetector carga el modelo desde assets, ejecuta inferencia y aplica NMS (Non-Maximum Suppression). El DetectionOverlay dibuja bounding boxes de colores sobre el vídeo FPV con etiquetas de clase y confianza. Un botón de ojo en la esquina permite activar o desactivar la detección, y un badge muestra el número de objetos detectados y los FPS de inferencia.

El primer intento de integración provocó un fallo en la aplicación al entrar en la pantalla de vuelo. El culpable: el GPU Delegate de TensorFlow Lite lanzaba un NoClassDefFoundError en el Moto G73, que es un Error de la JVM, no una Exception. Mi recolector de eventos no lo pillaba. Quedó corregido con catch (e: Throwable), con lo que detector cae elegantemente a CPU.
El segundo problema fue más sutil: las cajas de detección aparecían en la esquina superior izquierda, diminutas y lejos del objeto. El modelo TFLite INT8 devuelve coordenadas ya normalizadas (rango 0-1), pero mi código las dividía otra vez por el tamaño de entrada (416), aplastándolas a valores microscópicos. Una vez eliminada la doble normalización, las cajas se posicionaron correctamente sobre los objetos detectados.
La validación final: con la aplicación instalada en el Moto G73 y el dron conectado, activé la detección y me puse delante de la cámara. El overlay mostró «pedestrian 61%» con una caja correctamente posicionada alrededor de mi cara, a 3-4 FPS en CPU. No es espectacular, pero es suficiente para alertar al operador de la presencia de personas u objetos durante el vuelo.
Tercer paso. Análisis batch de fotos en el servidor
La tercera pieza del puzzle es un contenedor separado, photo-analyzer, que analiza las fotos de alta resolución (12-48 MP) descargadas del dron después del vuelo. A diferencia del stream RTMP a 720p que procesa el ai-processor en tiempo real, aquí se trabaja con las fotos completas que se usan para la ortofotografía.
La clave técnica es SAHI: cada foto se divide en mosaicos de 640×640 con un 25% de solapamiento, se ejecuta la inferencia sobre cada mosaico, y después se reensamblan las detecciones eliminando duplicados en las zonas de solapamiento. Esto permite detectar objetos pequeños que se perderían al redimensionar una foto de 48 MP a 640×640 directamente.
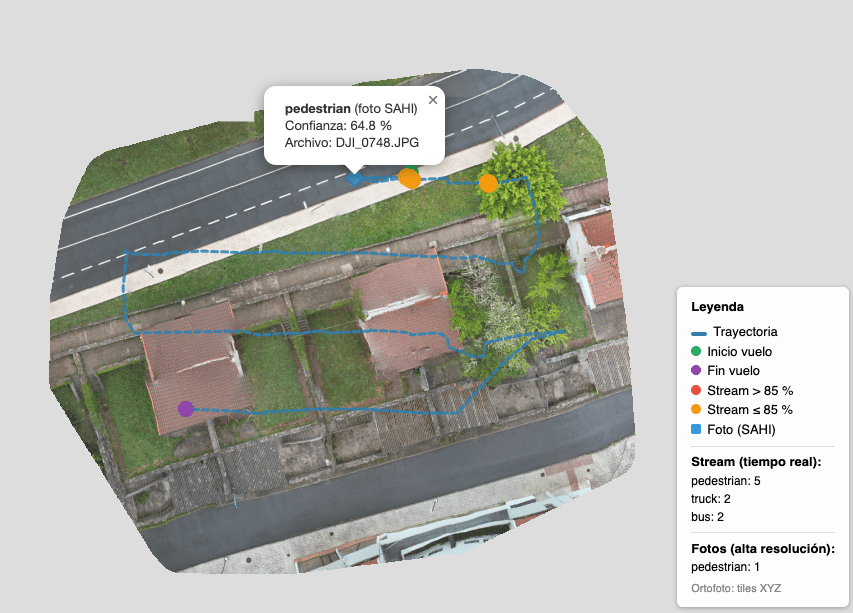
El photo-analyzer expone una API FastAPI en el puerto 8003, y audit-api actúa como proxy con un endpoint POST /audit/flights/{id}/analyze-photos que encola el trabajo. Las detecciones se almacenan en una nueva tabla PostGIS (photo_detections) con geometría georreferenciada extraída del EXIF GPS de cada foto, y se exponen como GeoJSON en una capa separada del visor Leaflet.
Cuarto paso. Preparación para fine-tuning continuo
El modelo VisDrone es un buen punto de partida, pero su dominio consiste en escenas urbanas densas. Si algún día necesito detectar objetos específicos de mi caso de uso (tejados dañados, paneles solares, infraestructuras agrícolas) necesitaré ajuste fino con datos propios. Esta wave prepara la infraestructura de versionado de modelos: una tabla en PostGIS que registra cada versión con su SHA256, fecha de entrenamiento, dataset, número de epochs y mAP de validación.
El flujo iterativo queda documentado: volar, revisar detecciones, anotar 200-500 fotos en Roboflow (aquí sí es útil como herramienta de anotación gratuita) o CVAT, fine-tune en Kaggle partiendo del modelo VisDrone como transfer learning, validar, exportar a ambos formatos, desplegar y comparar. Todo el pipeline a coste cero.
El papel de los asistentes IA en la toma de decisiones
Un aspecto que merece mención aparte es cómo he usado la orquestación de múltiples asistentes IA para tomar decisiones informadas, precisamente gracias a la integración que explicaba al inicio mediante MCPs. Claude Code sigue siendo el agente principal de desarrollo, pero en esta fase se ha apoyado en agentes de IA adicionales, mediante sendos MCPs específicos:
- ChatGPT como abogado del diablo: cada decisión arquitectónica importante (Roboflow frente a Ultralytics, TFLite frente a ONNX, separación de contenedores) se validó enviando la propuesta a ChatGPT con instrucciones de buscar debilidades, identificar riesgos y proponer alternativas. El resultado fue que se descartó Roboflow antes de invertir una sola hora de implementación, y se identificó la limitación de GSD del Mini 3 Pro para detección de grietas (menos de 1 píxel a 30 metros).
- NotebookLM para investigación técnica: se usó para evaluar en profundidad la viabilidad de Ultralytics en hardware sin GPU, investigar formatos de exportación y sus implicaciones de rendimiento, y recopilar benchmarks de referencia para el Xeon E5.
Esta dinámica de «consulta experta» a través de MCPs es algo que no había explorado hasta ahora en este proyecto, y la experiencia ha sido sorprendentemente productiva. No sustituye el criterio del desarrollador, pero aporta una segunda opinión técnica instantánea que habría requerido horas de investigación manual.
Resultado final
La Fase 9 ha transformado el sistema de un pipeline de captura pasivo a uno con percepción activa a dos niveles:
- En vuelo: el operador ve detecciones en tiempo real sobre el vídeo FPV, a 3-4 FPS en CPU, con un selector para activar/desactivar según necesidad.
- Post-vuelo: el servidor analiza cada foto de alta resolución con SAHI, detectando objetos que serían invisibles en el stream de 720p, y los geolocaliza automáticamente usando los metadatos EXIF.
El modelo VisDrone entrenado reduce las detecciones del genérico de 105 a 9, eliminando la mayoría de falsos positivos y produciendo resultados coherentes con la realidad observada. Y todo ello con un stack completamente gratuito: Ultralytics + Kaggle + TFLite + SAHI. Sin suscripciones, sin APIs de pago, sin limitaciones artificiales.
Para la siguiente fase del proyecto, la fase 10, tengo algunas ideas en la cabeza, como por ejemplo: mejoras de UX, soporte multi-dron, capas WMS del Catastro y SIGPAC, y la infraestructura de seguridad y monitorización que el servidor merece. A su debido tiempo trabajaré en esta nueva fase.




1 comentario en «Aplicación Android para fotogrametría con IA. Fase 9: Detección inteligente de objetos a dos niveles, dispositivo y servidor»