Creación de artículos deportivos con IA generativa
La aplicación sigue una arquitectura moderna y escalable, aprovechando las capacidades de Supabase para el backend y las funciones Edge para las integraciones con APIs externas y la IA.
1. Frontend
- Tecnología: React, TypeScript, Vite.
- Estilo: Tailwind CSS con componentes Shadcn/ui para una interfaz de usuario moderna y responsiva.
- Navegación: React Router para la gestión de rutas.
- Gestión de Estado:
react-querypara la gestión de datos asíncronos yuseSessionpara el contexto de autenticación. - Notificaciones:
sonnerpara mensajes de éxito/error/carga.
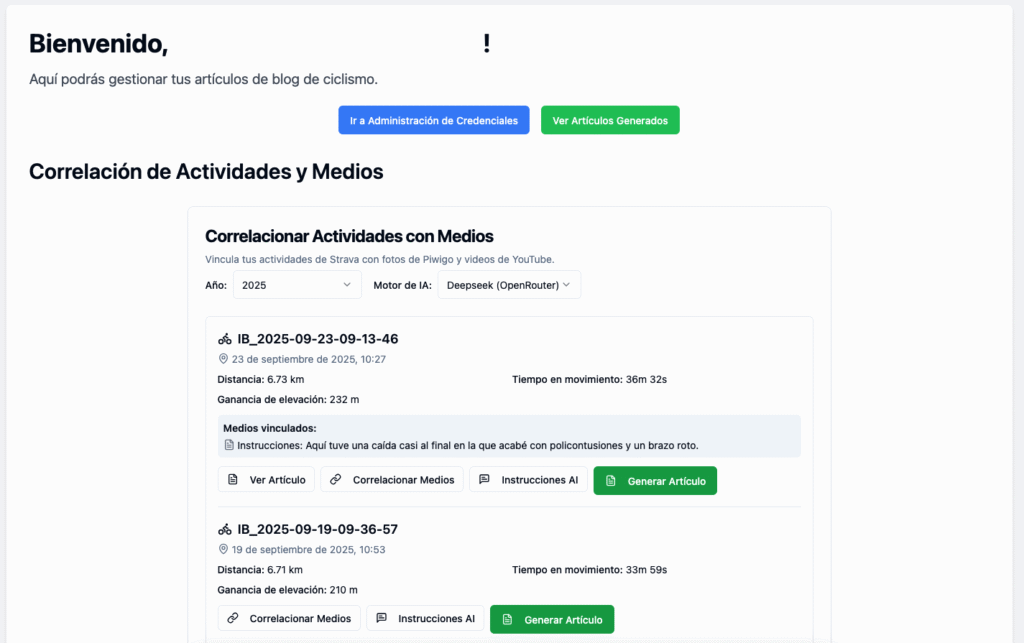
La aplicación se despliega en mi entorno de virtualización, específicamente en un servidor de backend de propósito general. La aplicación que se presenta permite, en un primer lugar, gestionar las integraciones con las distintas fuentes de datos (Strava, Piwigo, YouTube), el blog de destino (WordPress).
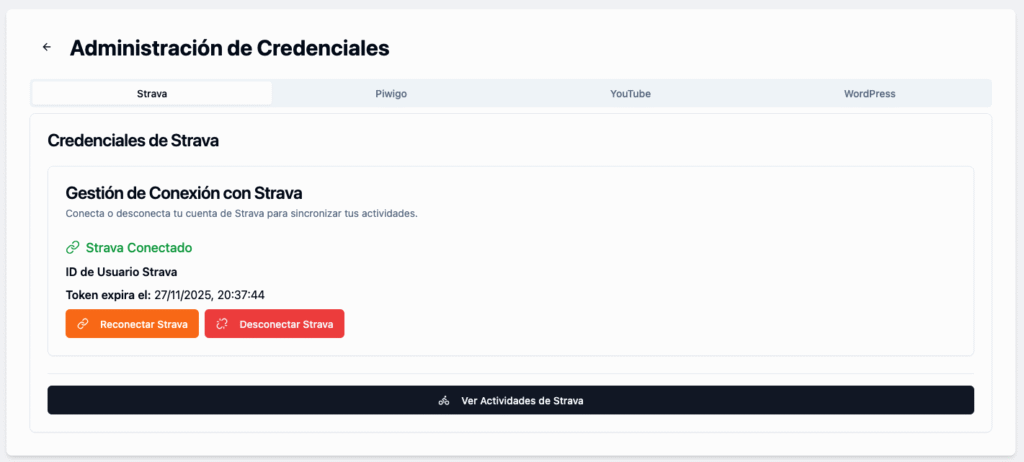
Las credenciales de cada uno de los orígenes o destinos de datos son gestionadas a través de una sección de administración. En el caso de Strava, es necesario gestionar un token que requiere de renovación periódica; en el caso de Piwigo, mediante usuario/contraseña, y en el de YouTube, a través de una API del canal. Con respecto a WordPress, se realiza mediante usuario/contraseña, con respecto a la API específica que permite gestionar la creación de artículos.
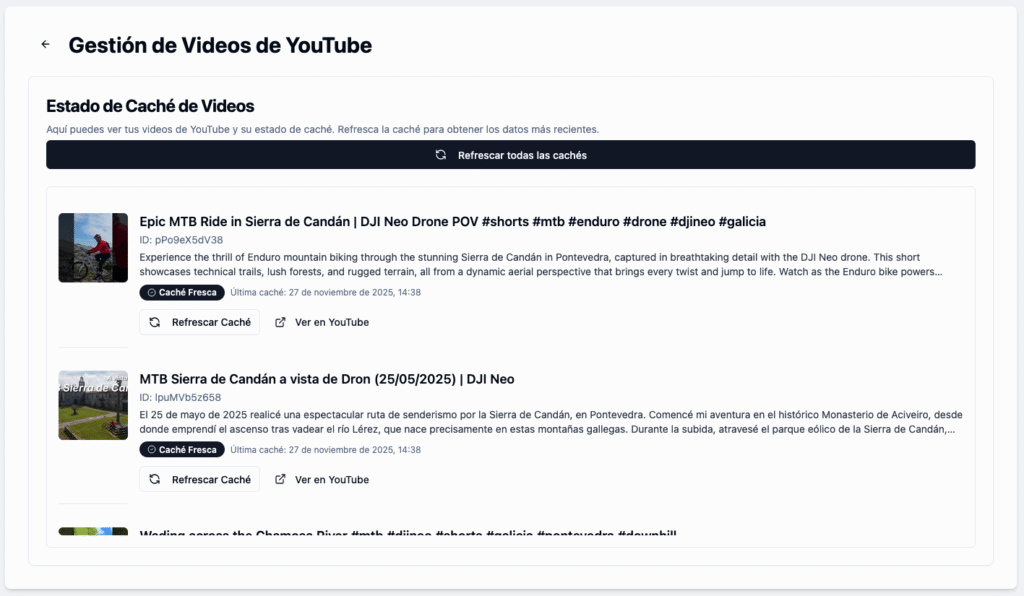
Para cada una de las fuentes de datos se ha habilitado un cacheado de contenido (recorridos, galerías, artículos), a fin de evitar excesivas consultas a las fuentes que puedan resultar en un bloqueo de las consultas a la API (algo que experimenté en el caso de YouTube durante las primeras fases del desarrollo). Esto permite reducir al mínimo las llamadas a las APIs. Para cada una de las fuentes se puede consultar el estado de las cachés, renovarlo de manera individual para cada uno de los registros, o bien de manera masiva para todo el contenido:
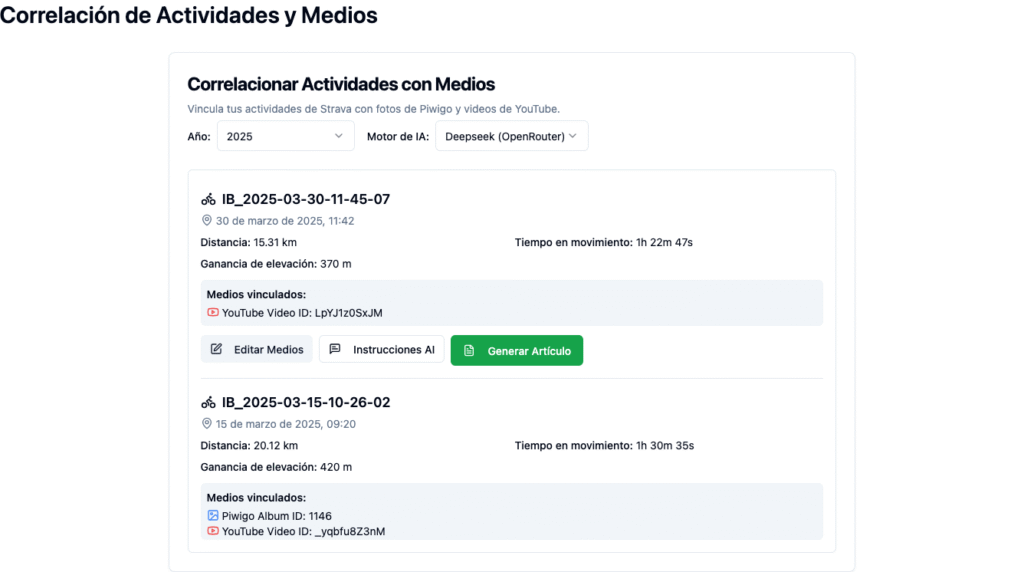
Una vez gestionadas las credenciales, es posible empezar el proceso de correlación en la interfaz principal. En la misma se muestran un listado de las activididades registradas en Strava, clasificadas por año. Para cada una de ellas es posible buscar correlaciones con las galerías de Piwigo y el canal de YouTube existentes. Una vez encontradas estas correlaciones, se puede proceder a generar el artículo, escogiendo el motor de IA preferido (DeepSeek o Mistral AI), e incorporando directrices específicas por parte del usuario:
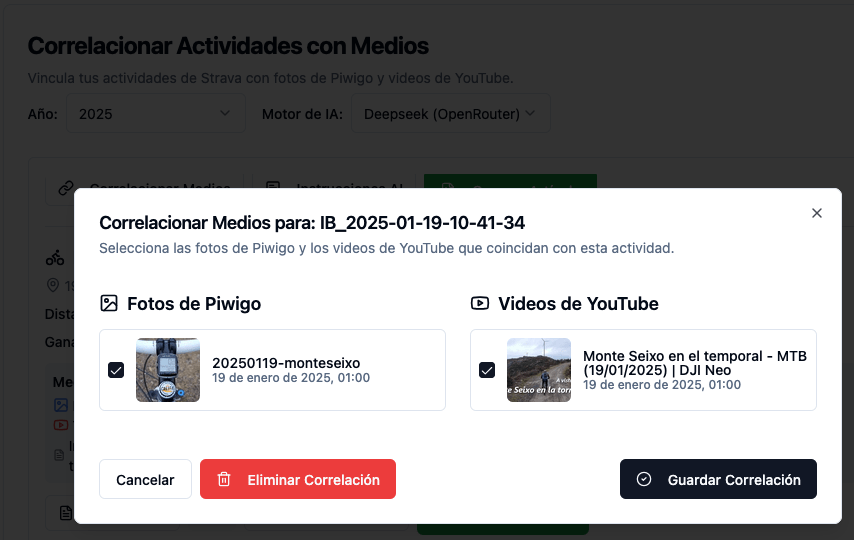
Tras confirmar la correlación de actividades con medios, si existen, y una vez introducidas las instrucciones adicionales para la IA, se puede generar el artículo.
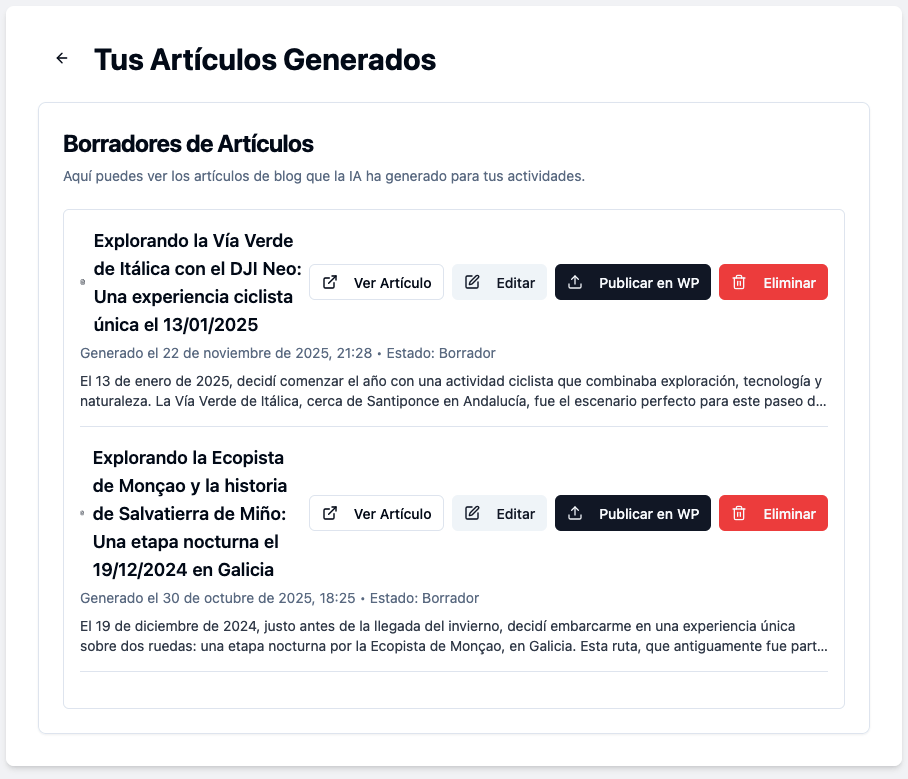
El sistema permite revisar los borradores de manera previa a su traslado al blog de WordPress, por si se quiere realizar alguna modificación antes de su envío.

Una vez enviado el artículo a WordPress, se almacena como borrador, para permitir al usuario controlar de manera completa el proceso de publicación del contenido, realizar los últimos cambios, añadir tags, categorías, etc…
2. Backend (Supabase & Edge Functions)
El corazón de la lógica de integración y generación de contenido reside en las Supabase Edge Functions, que se ejecutan en un entorno Deno. Esto permite una lógica de servidor sin necesidad de gestionar un servidor tradicional.
- Base de Datos: Supabase PostgreSQL para almacenar:
- Perfiles de usuario (
public.profiles). - Credenciales de cuentas externas (Strava, Piwigo, YouTube, WordPress) de forma segura, vinculadas al
user_idde Supabase Auth. - Correlaciones entre actividades de Strava y medios (
activity_media_correlations), incluyendo las instrucciones de la IA. - Artículos de blog generados (
generated_posts), con su estado y, si aplica, elwordpress_post_id. - Cachés de datos de APIs externas (actividades de Strava, categorías de Piwigo, videos de YouTube, estaciones y datos diarios de AEMET) para optimizar el rendimiento y reducir llamadas a APIs externas.
- Perfiles de usuario (
- Autenticación: Supabase Auth para la gestión de usuarios.
- Row Level Security (RLS): Implementado en todas las tablas para asegurar que los usuarios solo puedan acceder a sus propios datos.
A continuación se muestra como ejemplo parte de la tabla que cachea la relación de estaciones meteorológicas de la AEMET a nivel nacional. La idea es poder obtener la estación meteorológica más cercana a la actividad para la que se genera el contenido.
Una vez determinada la estación más cercana, se accede a la información meteorológica del día de la actividad. Lo ideal sería tener un registro horario, pero la AEMET sólo ofrece información con una granularidad a nivel de día, y no de hora. Esta información se almacena como un JSON que posteriormente se proporciona a la IA generativa para enriquecer el artículo con información meteorológica general de la jornada.

3. Integraciones Externas
La aplicación se conecta con varias APIs externas a través de las Edge Functions:
- Strava API: Para obtener las actividades del usuario.
- Piwigo API: Para acceder a álbumes y fotos, incluyendo metadatos EXIF de geolocalización.
- YouTube Data API: Para obtener detalles de videos de un canal específico.
- WordPress REST API: Para publicar artículos de blog.
- DeepSeek API (vía OpenRouter): Para la generación de contenido de los artículos de blog.
- Mistral AI API: Para la generación de contenido de los artículos de blog. Se usa de manera alternativa a DeepSeek.
- AEMET OpenData API: Para obtener información meteorológica histórica de las ubicaciones de las actividades.
- Nominatim (OpenStreetMap): Para geocodificación inversa de coordenadas a nombres de lugares.