

Llevo unos meses dándole vueltas a una idea que ha ido tomando forma casi sin que me diera cuenta. Empezó como un fogonazo mental cuando estaba trabajado en un proyecto, en el que visualicé un esquema que me daba un ordenado funcional que se podía aplicar a las tres herramientas de IA que más utilizo en mi día a día: Claude Code, NotebookLM y ChatGPT. Cada una hacía algo distinto, cada una era buena en lo suyo, y yo me pasaba el día saltando entre pestañas del navegador como un mensajero, copiando texto de un sitio para pegarlo en otro, perdiendo contexto en cada salto, y enfadándome cada vez que tenía que repetirle a una IA algo que otra ya sabía perfectamente. Había empezado a trabajar en un flujo de interacción con IAs que, si bien funcionaba, no era lo más ágil del mundo. Búsqueda documental y perfilado de un concepto preliminar en NotebookLM, validación de ese concepto preliminar en Claude Code para tener una implementación concreta, y pulido de esa implementación en ChatGPT. Adecuado, pero engorroso. Hasta que descubrí los MCP, y entonces todo encajó.

Este artículo va de cómo se construye lo que he acabado llamando un Agente de Ingeniería Total: un asistente que combina la capacidad de ejecución local de Claude Code con la memoria corporativa de NotebookLM, el razonamiento alternativo de ChatGPT, y otras tantas integraciones (Blender, Google Colab, Google Drive) que convierten un terminal en una mesa de trabajo donde todas las herramientas están al alcance del agente sin necesidad de que yo me levante a buscarlas. Es, en esencia, una forma muy concreta de aprovechar el Model Context Protocol, el estándar que está cambiando radicalmente cómo los humanos interactuamos con la IA o, más bien, cómo la IA interactúa con todo lo demás.
El problema: la IA aislada no sirve para tareas reales de ingeniería
Antes de meternos en harina conceptual, conviene entender por qué este planteamiento tiene sentido. Cualquiera que haya trabajado con IA generativa para tareas de ingeniería se ha encontrado con la misma pared: el modelo es brillante hasta que necesita información del mundo real. Le pides a ChatGPT que te diseñe un módulo de autenticación y lo hace, pero ignora completamente que tu empresa tiene una guía de estilo que dice que toda autenticación debe pasar por un proveedor SAML específico. Le pides a Claude que te refactorice un servicio y lo hace bien, pero no sabe que ese servicio se despliega en un Kubernetes con unas restricciones de red muy concretas que están documentadas en un repositorio que solo tú has leído.
El resultado, a la práctica, es que el cuello de botella deja de ser la IA y pasa a ser uno mismo. Tú eres quien tiene que ir leyendo la documentación, extrayendo lo relevante, copiándolo al prompt, pegando la respuesta en el editor, ejecutando el comando en la terminal, y volviendo a copiar el resultado al chat para preguntar qué hacer con el error que ha salido. La IA tiene el cerebro, pero tú tienes las manos, los ojos y la memoria. Y eso, en ingeniería, no escala.
Lo que cambia con los MCP es precisamente eso: la IA deja de ser un interlocutor con el que conversamos en una caja de texto y pasa a ser un agente que tiene acceso directo a las herramientas, datos y sistemas que necesita para hacer su trabajo. Y todo ello sin que tú hagas de intermediario.
Qué es el Model Context Protocol (MCP) y por qué importa
El Model Context Protocol es un estándar abierto, originalmente creado por Anthropic en noviembre de 2024 y donado en diciembre de 2025 a la Agentic AI Foundation de la Linux Foundation, que define una manera estandarizada de conectar modelos de lenguaje (LLMs) con fuentes de datos, herramientas y servicios externos. La analogía que más me gusta (y que vi por primera vez en la documentación de Codecademy) es la del puerto USB-C para aplicaciones de IA: en lugar de tener un cable distinto para cada periférico, tienes un único conector universal que sirve para todo.

Antes de la existencia de los MCP, conectar un modelo a una herramienta externa requería una integración personalizada para cada pareja modelo-herramienta. Si querías que ChatGPT leyera tu Google Drive, hacía falta un plugin específico de OpenAI. Si querías que Claude consultara tu base de datos, hacía falta una integración propietaria de Anthropic. Esto generaba lo que en la documentación oficial llaman el problema N×M: N modelos por M herramientas dan como resultado N×M integraciones distintas, todas ellas mantenidas por separado. Una pesadilla de fragmentación.
MCP resuelve esto introduciendo una capa intermedia. En lugar de N×M integraciones, hay N+M: cada modelo implementa el protocolo MCP como cliente, cada herramienta lo implementa como servidor, y cualquier cliente puede hablar con cualquier servidor. Es exactamente el mismo principio que aplicó el Language Server Protocol al mundo de los IDEs hace una década, permitiendo que cualquier editor de código (VS Code, Vim, Emacs…) hable con cualquier analizador de lenguaje (TypeScript, Python, Rust…) sin necesidad de integraciones específicas. De hecho, MCP se inspira directamente en LSP y reutiliza muchas de sus ideas de diseño, transportando los mensajes sobre JSON-RPC 2.0.
La arquitectura: clientes, servidores y primitivas
Un sistema MCP tiene tres piezas conceptuales:
- El host es la aplicación con la que tú interactúas: Claude Code, Claude Desktop, Cursor, ChatGPT con apps, etc. Es el que tiene el modelo de lenguaje y gestiona la conversación.
- El cliente MCP es el componente dentro del host que sabe hablar el protocolo. Lo lanzas y se queda escuchando lo que el modelo necesita.
- El servidor MCP es lo que expone una capacidad concreta — leer tu Google Drive, ejecutar código en Blender, consultar tu base de datos, lo que sea — usando el lenguaje común del protocolo.
Lo bonito es que el servidor no sabe ni le importa qué modelo está al otro lado. Puede ser Claude Opus 4.7, GPT-5, Gemini o un modelo local que estés ejecutando con Ollama. Y al revés: el cliente no necesita saber cómo está implementado el servidor por dentro; solo necesita saber qué capacidades expone.
Esas capacidades se agrupan en tres primitivas que el protocolo define formalmente:
- Tools (herramientas): funciones que el modelo puede invocar. Por ejemplo, una herramienta
create_blender_objectque recibe parámetros y crea un cubo en Blender. Son model-controlled: es el propio modelo el que decide cuándo y cómo invocarlas, en función de lo que esté intentando conseguir. - Resources (recursos): datos que el modelo puede leer pero no ejecutar. Por ejemplo, el contenido de un fichero, la respuesta de una API, las filas de una base de datos. Son application-controlled: el host decide qué recursos cargar en el contexto.
- Prompts (prompts): plantillas predefinidas que ayudan al usuario a invocar comportamientos complejos del servidor. Son user-controlled: el humano elige cuál disparar.
En la práctica, la mayoría de los MCPs que vas a encontrar y a usar exponen sobre todo tools. Las otras dos primitivas son más sutiles y aparecen en casos más sofisticados.
Adopción real: por qué esto va en serio
Uno de los indicios más claros de que MCP no es una moda pasajera es la velocidad a la que lo ha adoptado todo el sector. OpenAI lo integró oficialmente en marzo de 2025, primero en la desktop app de ChatGPT y en septiembre de 2025 también en las ChatGPT apps. Microsoft Semantic Kernel y Azure OpenAI lo soportan. Cloudflare permite desplegar servidores MCP en su infraestructura edge. Y, como decía antes, en diciembre de 2025 Anthropic transfirió la gobernanza del protocolo a la Linux Foundation, lo que lo convierte definitivamente en un estándar de la industria y no en la herramienta propietaria de un fabricante. Hoy se hablan de miles de servidores MCP construidos por la comunidad, con SDKs disponibles en Python, TypeScript, C#, Java, Kotlin y otros lenguajes.
Esto importa porque significa que cualquier inversión que hagas hoy en aprender a desplegar y usar MCPs es una inversión que va a tener retorno durante años, y porque garantiza que tu trabajo no quedará atrapado en el silo de un único fabricante. Si mañana cambio Claude por otro modelo, todos mis servidores MCP siguen funcionando exactamente igual.
Por qué Claude Code es el centro de gravedad del sistema
Antes de entrar en los MCPs concretos que tengo montados, conviene explicar por qué Claude Code, y no otro entorno, es el núcleo del agente que estoy describiendo.
Claude Code es la herramienta de Anthropic para programación agéntica desde la línea de comandos. Lo que la distingue de un chat tradicional no es solo el modelo (Claude Opus 4.7 en la versión actual, que ya es bastante distinguible por sí solo), sino el conjunto de capacidades nativas que tiene integradas en el propio agente: lee y edita archivos, ejecuta comandos en bash, hace git commit, navega por la estructura de un repositorio, ejecuta tests y analiza sus salidas. Es, literalmente, un ingeniero al que le dejas las manos sobre tu teclado.
Y, lo que es más importante para lo que nos ocupa, Claude Code es uno de los hosts MCP más maduros que hay disponibles. La integración no es un añadido post hoc; es parte del diseño del producto. Tiene gestión de permisos para cada herramienta MCP, control sobre los tokens que consumen las salidas de los servidores, y un sistema de tool search que permite trabajar con cientos de herramientas MCP sin saturar la ventana de contexto del modelo (las herramientas se cargan a demanda cuando el modelo decide que las necesita, no todas al inicio).
Esto último, que parece un detalle técnico menor, es crítico. Cuando tienes diez servidores MCP conectados, cada uno con quince o veinte herramientas, las definiciones de esas herramientas — sus nombres, parámetros, descripciones — pueden ocupar decenas de miles de tokens en el contexto. Si todas se cargan al inicio, el modelo arranca cada conversación arrastrando un lastre considerable. El tool search de Claude Code resuelve esto: las definiciones se mantienen disponibles pero ocultas hasta que el modelo busca activamente alguna capacidad que las necesite. El efecto es que puedes tener un agente con acceso a una superficie enorme de herramientas sin pagar el coste en cada turno de conversación.
Mi Santísima Trinidad: Claude Code + NotebookLM + ChatGPT
La primera versión del Agente de Ingeniería Total que diseñé combinaba tres bloques con responsabilidades muy distintas, en lo que vine a llamar mi Santísima Trinidad de la IA. Una pieza de ingeniería robusta, potente, y destinada a proporcionar una supremacía en la ingeniería de sistemas IT. No se me solivianten los católicos. Esto no va de religión, sino de diseño funcional. Conviene explicarlos uno a uno antes de entrar en el resto de integraciones que he ido sumando con el tiempo, porque cada uno cubre un eje conceptual diferente:
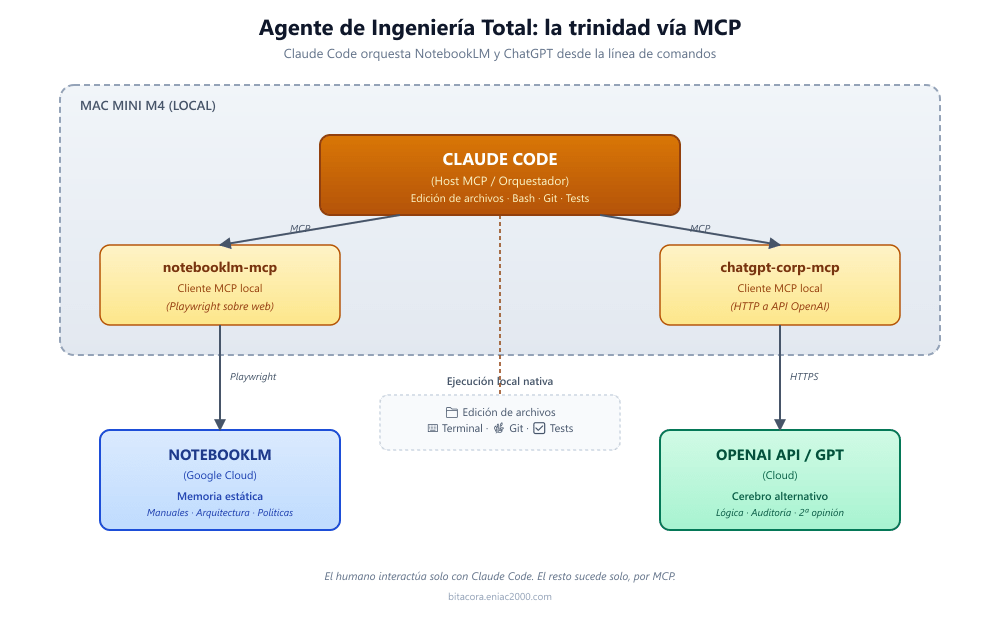
NotebookLM: la memoria corporativa estática
NotebookLM es la herramienta de Google que te permite cargar un corpus de documentos (PDFs, transcripciones, páginas web, notas de Google Docs) y conversar con ellos. Es lo que en la jerga llamamos un sistema RAG (Retrieval-Augmented Generation): tú haces una pregunta, el sistema busca en tus documentos los fragmentos más relevantes, y se los pasa al modelo junto con la pregunta para que genere una respuesta apoyada en ese contenido.

Lo que hace especial a NotebookLM frente a otros sistemas RAG es la calidad de su grounding: cada afirmación que hace el sistema viene con una referencia exacta al pasaje del documento del que la ha extraído. Esto es oro puro en un contexto de ingeniería, donde necesitas poder verificar de dónde sale cada decisión.
En el agente, NotebookLM ocupa el rol de memoria corporativa estática. Aquí cargo los documentos que definen el contexto en el que el agente debe operar: manuales de arquitectura, guías de estilo de código, políticas de seguridad, decisiones arquitectónicas del proyecto, especificaciones de proveedores externos, normativa relevante (en mi caso, mucha legislación AESA sobre drones, por ejemplo). Es información que cambia poco y que el agente debe poder consultar en cualquier momento.
El servidor MCP que utilizo para conectar NotebookLM con Claude Code es un proceso local que, por debajo, automatiza la interacción con la interfaz web de NotebookLM mediante Playwright (NotebookLM no expone una API pública oficial todavía). Funciona como un puente: Claude Code le pregunta «¿qué dicen los documentos sobre el procedimiento de despliegue en producción?», el MCP traduce esa pregunta en una sesión de NotebookLM, recoge la respuesta con sus citas, y la devuelve al agente.
ChatGPT: el cerebro analítico externo
El segundo vértice de la trinidad es ChatGPT, a través de la API de OpenAI. ¿Por qué meter dos modelos de lenguaje en el mismo sistema, cuando Claude ya es perfectamente capaz por sí solo? La respuesta, para mí, es la del segundo par de ojos.

Modelos distintos tienen sesgos distintos, entrenamientos distintos, fortalezas distintas. Claude tiende a ser excelente en código bien estructurado y en seguir instrucciones complejas con muchos matices. GPT, en mi experiencia, tiene un punto fuerte en problemas de lógica abstracta y en exploraciones algorítmicas donde hay que probar varias rutas mentalmente antes de decidirse por una. No es que uno sea mejor que el otro; es que son diferentes, y para tareas críticas (como revisar una función que va a manejar credenciales, o validar un esquema de cifrado) el contraste entre dos perspectivas independientes vale más que la opinión más fuerte de cualquiera de ellos.
El MCP corporativo de ChatGPT que tengo configurado expone básicamente un par de tools: una para preguntas de razonamiento técnico y otra para auditorías de código. Por debajo hace una llamada HTTP a la API de OpenAI, con un system prompt específico para cada tipo de consulta. Desde Claude Code, invocar a GPT es tan sencillo como mencionarlo: «ChatGPT, revisa esta función auth.ts, especialmente la lógica de validación de tokens».
El valor de esta integración aumenta cuando se combina con la siguiente.
Claude Code: la capacidad de ejecución local
El tercer vértice es Claude Code mismo, en su rol no de host orquestador, sino de ejecutor. Las herramientas nativas que mencionaba antes — editar archivos, ejecutar bash, hacer commits — son las que convierten todo el sistema en algo más que un asistente conversacional. Claude Code es el que, al final de la cadena, modifica el código real, lo ejecuta, observa el resultado y decide el siguiente paso.

Cuando se juntan los tres elementos, el flujo de trabajo cambia drásticamente. Un ejemplo concreto, sacado de un proyecto reciente:
- Yo pregunto: «Necesito implementar la autenticación del nuevo microservicio. Mira en NotebookLM qué proveedor SAML usamos como estándar, pídele a ChatGPT que diseñe el flujo de tokens incluyendo refresh, y luego implementa la función
authenticateRequestensrc/auth/handler.ts». - Claude Code consulta NotebookLM y descubre que el estándar de la organización es Okta con tokens JWT firmados con RS256 y una rotación de 15 minutos.
- Con esa información, prepara un prompt para ChatGPT que incluye los requisitos específicos, pidiéndole que diseñe el flujo de autenticación.
- ChatGPT devuelve un esquema con los pasos del flujo de tokens, incluyendo manejo de refresh y casos de error.
- Claude Code traduce ese esquema en código TypeScript real, lo escribe en el archivo correspondiente, ejecuta los tests, y si algo falla, vuelve a iterar.
Yo, en todo este proceso, intervengo dos veces: al inicio para dar la instrucción, y al final para revisar el commit que Claude propone hacer. Lo que antes me llevaba una mañana entera saltando entre pestañas ahora son diez minutos de supervisión.
Un paréntesis naval: el otro Santísima Trinidad
Si hablas de «trinidad» y de «ingeniería» en la misma frase, y siendo uno español, es prácticamente obligatorio detenerse un momento en el Santísima Trinidad. Con artículo masculino, porque hablamos del navío, no de la advocación mariana. El juego de palabras es deliberado y conviene desarrollarlo, porque los paralelismos entre aquel coloso del XVIII y este agente de IA del XXI son más reveladores de lo que parecen a primera vista.
El Nuestra Señora de la Santísima Trinidad fue botado en los astilleros de La Habana en octubre de 1769 y se convirtió, tras sucesivas reformas, en el mayor navío de línea de su tiempo y el único del mundo con cuatro puentes de cañones. En su configuración previa a Trafalgar montaba 140 piezas de artillería (32 cañones de 36 libras en la cubierta más baja, 34 de 24 libras en la segunda, 36 de 12 libras en la tercera, otros tantos más ligeros arriba, además de obuses y esmeriles), desplazaba casi 5.000 toneladas y embarcaba a más de 1.100 hombres entre tripulación y guarnición. Se le llamaba El Escorial de los mares, y no era para menos: era el buque insignia de la Armada Española y el símbolo flotante del poderío marítimo de un imperio que aún se resistía a aceptar que el siglo se le estaba escapando entre los dedos.
Lo que hace al Santísima Trinidad interesante para esta historia, sin embargo, no es su porte sino su concepto de integración. Diseñado inicialmente por el irlandés Matthew Mullins (castellanizado en Mateo Mullan), continuado por su hijo Ignacio tras la muerte del padre, y construido con maderas tropicales (caoba, júcaro, caguairán) transportadas desde Camagüey hasta los astilleros habaneros, era una pieza de ingeniería que combinaba lo mejor que la metrópoli y las colonias podían aportar. Un proyecto irlandés-español, materiales caribeños, mano de obra cubana, refinamientos posteriores en Ferrol y Cádiz. Ninguno de esos elementos por separado habría producido nada extraordinario; juntos, dieron el navío más imponente que jamás había surcado los mares.
El paralelismo con un Agente de Ingeniería Total empieza a ser visible. Ni Claude Code por sí solo, ni NotebookLM por sí solo, ni la API de OpenAI por sí sola producen nada cualitativamente nuevo: son herramientas excelentes pero limitadas a su dominio. Es la integración lo que cambia la categoría del resultado. Y, como en el caso del navío, el valor está en la composición, no en cada pieza aislada.
Hay una segunda lectura, sin embargo, que no conviene pasar por alto, porque es la que da profundidad al paralelismo. El Santísima Trinidad fue una ingeniería problemática desde el primer día. Tuvo problemas estructurales prácticamente toda su vida útil. Las pruebas de mar de 1770, pocos meses después de su botadura, revelaron que su punto de escora era tan elevado que en mares poco calmados no podía utilizar la cubierta inferior de cañones. Fue carenado y reformado una y otra vez en Ferrol y en La Carraca. En 1795 se le añadió la cuarta cubierta, decisión que el historiador Cesáreo Fernández Duro criticaría con dureza años después, sugiriendo que con el coste de las reparaciones acumuladas se podría haber construido un navío entero «de oro», y que la lógica habría aconsejado recortarlo en lugar de ampliarlo. La ambición de añadir más capacidad de fuego a un casco que ya iba justo de estabilidad fue, en última instancia, lo que selló su destino en Trafalgar: un navío inmenso, pero pesado y poco maniobrable, que acabó batiéndose solo contra siete buques británicos antes de ser capturado y, dos días después, hundido por un temporal frente a Cádiz.
La lección, traducida al lenguaje del software, es clara: la integración compleja tiene tendencia a volverse inestable cuando se le añaden capacidades por encima de su diseño original. Cada MCP nuevo es una cubierta más de cañones. Multiplica la potencia de fuego del sistema, sí, pero también su peso, su superficie de fallo, su consumo de tokens, su latencia, su complejidad operativa. Llega un momento en que añadir otro servidor MCP no compensa: el agente empieza a marearse en su propio contexto, las herramientas se pisan unas a otras, y lo que era una orquestación se convierte en una cacofonía.
Por eso, cuando hablo de el Santísima Trinidad como referencia para la trinidad de mi agente, lo hago con dos sentimientos a la vez. Por un lado, una admiración genuina por lo que la integración bien hecha puede conseguir: un sistema que es cualitativamente superior a la suma de sus partes. Por otro, una conciencia clara de que la grandeza arquitectónica no es garantía de robustez. El Trinidad real se fue a pique entre otras razones porque cada generación de reformistas quiso añadirle algo más sin cuestionar si el casco lo aguantaba. Cuando uno monta un sistema de IA agéntica, la tentación es exactamente la misma: «¿y si le añado también un MCP para…?». La respuesta, muchas veces, es que no. Que el sistema actual funciona, que ya tiene cuatro cubiertas, y que la quinta puede ser la que lo hunda.
Conviene recordarlo cada vez que uno se siente delante del terminal con un nuevo servidor MCP recién compilado y la mano sobre el config.json. La ingeniería maestra no consiste en meterlo todo; consiste en saber qué dejar fuera. Algo que en La Carraca, en 1795, se aprendió tarde. ⚓
Más allá del Trinidad: los MCPs que se han ido sumando
Volviendo a la IA y, una vez que tienes tu Santísima Trinidad funcionando, el sistema se vuelve adictivo, por muchas advertencias históricas que tengas en mente. Cada vez que te encuentras saltando entre pestañas, copiando datos de una herramienta a otra, te preguntas si no habrá un MCP que cierre ese hueco. Y, normalmente, lo hay. O, si no lo hay, lo escribes tú — el SDK de MCP en Python permite montar un servidor funcional en menos de cien líneas de código. Estos son los tres MCPs adicionales que se han ganado un sitio fijo en mi entorno desde que diseñé el esquema original.
Blender: modelado 3D y postproducción de vídeo
El MCP de Blender es probablemente el que ha tenido un impacto más espectacular en mi trabajo creativo, y al que ya le dediqué un artículo entero en el proyecto del Teatro Romano de Itálica. La idea es la siguiente: Blender es una herramienta extraordinariamente potente, pero su interfaz tiene una curva de aprendizaje brutal. Hay decenas de paneles, miles de operadores, un sistema de shading nodal que requiere paciencia, y una nomenclatura de ejes que es distinta a la de prácticamente cualquier otra herramienta 3D del mundo.

Lo que el MCP hace es exponer la API de Python de Blender — que es muy completa, prácticamente cualquier cosa que se puede hacer con clicks se puede hacer con código — como un conjunto de herramientas accesibles desde Claude Code. Y, lo que es igual de importante, permite a Claude tomar capturas del viewport para verificar visualmente que el resultado se corresponde con lo que se esperaba.
Esto cambia completamente cómo se trabaja con Blender. En el artículo de Itálica, por ejemplo, importé un modelo fotogramétrico de 172.000 caras en coordenadas UTM, lo recorté para quedarme solo con el teatro romano, configuré iluminación y cámara, y generé cuatro renders distintos a 4K con trayectorias de cámara complejas. No abrí Blender ni una sola vez. Todo se hizo desde Claude Code, con capturas intermedias del viewport para verificar cada paso. Lo que con la interfaz gráfica me habría llevado días de fricciones se resolvió en una tarde de iteraciones.
El uso no se limita a renderizado de modelos fotogramétricos. Lo uso también para hacer maquetas rápidas de visualización para artículos, para preparar escenas que se combinarán con metraje real de dron, y para esquemas 3D que ilustran conceptos técnicos. Cuando necesito una imagen que no tengo, la modelo. Y cuando hay que mover una cámara virtual por una escena, lo hago con la precisión matemática que ofrece el código (curvas Bézier de cinco puntos, función smoothstep para suavizar arranques y frenadas, constraints de tipo Track To que apuntan a un objetivo móvil), no con el pulso aproximado del ratón.
Google Colab: procesamiento masivo con GPU
El Mac Mini M4 es una máquina extraordinaria, pero hay tareas para las que necesito más GPU. Entrenamiento de modelos personalizados, inferencia masiva sobre miles de imágenes, procesado de nube de puntos LiDAR con millones de muestras… son cargas que mi máquina local no puede afrontar de manera razonable, o que tardarían días en completar.
Google Colab resuelve esto con elegancia: te da acceso a GPUs (T4 en el plan gratuito, A100 o L4 en los planes de pago) a través de cuadernos Jupyter que viven en la nube. El MCP de Colab que tengo conectado permite a Claude Code crear cuadernos, subir datos, ejecutar celdas, leer los resultados, y descargar los outputs. Todo desde la línea de comandos.
Un ejemplo típico de uso es el de la detección de objetos con YOLOv8 sobre lotes grandes de fotogramas de dron, como contaba en la serie de Fotogrametría asistida por IA. Hacerlo localmente lleva horas. En Colab, con una T4, son minutos. El flujo es:
- Claude Code prepara los datos en local: lista de vídeos, modelo de YOLO ajustado, configuración del pipeline.
- A través del MCP, sube los archivos al Drive asociado a Colab y crea un cuaderno con el código necesario.
- Lanza la ejecución del cuaderno con la GPU activada y va monitorizando el progreso.
- Cuando termina, descarga los resultados (las detecciones, los bounding boxes, las imágenes anotadas) y los incorpora al proyecto local.
El punto interesante es que esto no requiere que yo deje de trabajar en otra cosa. Es procesado asíncrono, y Claude Code me avisa cuando hay resultados listos para revisar.
Google Drive: documentación automatizada de proyectos
El último MCP que se ha incorporado al stack es el de Google Drive, y es seguramente el menos espectacular pero el más útil en términos de productividad cotidiana. Anthropic publicó un servidor MCP oficial para Drive desde el principio, y lo tengo conectado para dos cosas concretas: lectura de documentación de referencia y escritura de documentación generada.
La lectura es el complemento natural de NotebookLM. NotebookLM es brillante para corpus estables, pero hay documentos que cambian a menudo (notas de reuniones, hojas de cálculo con métricas, especificaciones vivas) para los que cargar y recargar en un notebook es un engorro. Con el MCP de Drive, Claude Code puede leer directamente la versión actual de cualquier documento accesible para mí en mi Drive personal.
Pero el uso que realmente justifica el MCP es el de escritura. Cada proyecto técnico que monto genera, casi sin que me dé cuenta, una cantidad considerable de documentación: notas de decisiones de diseño, registros de incidencias, listas de tareas, esquemas de arquitectura. Antes, todo esto vivía en archivos Markdown dispersos por el sistema de archivos, lo que erar susceptible de que determinada documentación se perdiera o quedara desactualizada. Ahora, al cerrar una sesión de trabajo, le pido a Claude Code que actualice los documentos correspondientes en Drive: un resumen ejecutivo de lo que se ha hecho, un cambio en el documento de arquitectura si hemos tomado una decisión nueva, una entrada en el registro de cambios. Es la documentación que siempre se tiene que mantener, y que nunca mantenía, ahora mantenida sola.
El esquema completo: cómo encaja todo
Con los seis MCPs conectados, el esquema queda como sigue:
┌─────────────────────────────────────────────────────────────────┐
│ MAC MINI M4 │
│ │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ CLAUDE CODE (Orquestador / Host MCP) │ │
│ │ Edición de archivos · Bash · Git · Tests │ │
│ └──┬───────┬───────┬───────────┬───────────┬─────────┬───┘ │
│ │ │ │ │ │ │ │
│ │ MCP │ MCP │ MCP │ MCP │ MCP │ MCP │
│ ▼ ▼ ▼ ▼ ▼ ▼ │
│ ┌──────┐┌──────┐┌────────┐┌─────────┐┌─────────┐┌──────────┐ │
│ │ NLM ││ GPT ││ Blender││ Colab ││ Drive ││ otros... │ │
│ │ (PW) ││(HTTP)││ (PyAPI)││(HTTP+nb)││(REST) ││ │ │
│ └──┬───┘└──┬───┘└────┬───┘└────┬────┘└────┬────┘└──────────┘ │
└─────┼───────┼─────────┼─────────┼──────────┼────────────────────┘
│ │ │ │ │
▼ ▼ ▼ ▼ ▼
┌──────┐┌──────┐ ┌────────┐ ┌─────────┐ ┌──────────┐
│Note- ││OpenAI│ │Blender │ │Google │ │Google │
│bookLM││ API │ │(local) │ │Colab │ │Drive │
│(GCP) ││(GPT) │ │ │ │(GPU GCP)│ │(GCP) │
└──────┘└──────┘ └────────┘ └─────────┘ └──────────┘
Memoria Cerebro 3D + vídeo GPU Documentación
estática alterno + render compute versionadaEl centro de gravedad sigue siendo Claude Code. Es quien decide qué herramienta usar para cada subtarea, quien sintetiza las salidas de unas en las entradas de otras, y quien al final escribe el código y hace el commit. Los servidores MCP son los músculos; Claude Code es la corteza prefrontal.
Tres ventajas que justifican toda la complejidad
Conviene aquí pararse a pensar qué se gana realmente con todo esto. Porque la complejidad operativa de tener seis MCPs conectados no es trivial: cada uno tiene su configuración, sus credenciales, sus dependencias, sus posibles fallos. ¿Vale la pena?
1. El flujo de información se vuelve imbatible
La ventaja más obvia es la que ya he ido apuntando: eliminar el rol del humano como mensajero entre herramientas. Cuando le pides a Claude Code que «basándose en los estándares de seguridad de la empresa, le pida a ChatGPT que diseñe un esquema de autenticación, y lo implemente en auth.ts», lo que pasa por debajo es una orquestación de tres sistemas que, sin MCP, requerirían tu intervención manual al menos cuatro o cinco veces. Con MCP, requieren cero.
El ahorro de tiempo es real, pero lo que más se nota es el ahorro de contexto mental. Mantener en la cabeza qué pestaña tiene qué información, qué consulta había hecho en cuál, qué versión de la respuesta era la buena… es una carga cognitiva considerable, y cuando desaparece, te das cuenta de cuánto pesaba.
2. La tensión entre «grounding» e innovación se resuelve por arquitectura
Esta es, para mí, la ventaja conceptual más profunda. Cualquier proyecto de ingeniería real vive en una tensión constante entre dos fuerzas: por un lado, hay que respetar lo que ya existe (los estándares de la organización, las decisiones arquitectónicas previas, las limitaciones de los sistemas legacy) y por otro, hay que innovar, encontrar soluciones nuevas, no quedarse atrapado en lo de siempre.
Una IA conectada solo a documentación corporativa es conservadora hasta el aburrimiento: te repite lo que ya está escrito. Una IA sin documentación corporativa es brillante pero peligrosa: te propone soluciones técnicamente impecables que ignoran completamente el contexto en el que tienen que ejecutarse. El agente con la trinidad resuelve esto por diseño arquitectónico:
- NotebookLM mantiene al agente anclado en lo que la organización permite, requiere y tiene documentado.
- ChatGPT aporta la chispa de la solución técnica moderna, sin contaminarse de las restricciones internas.
- Claude Code actúa como árbitro: toma las restricciones de uno, la propuesta del otro, y las combina en una implementación concreta que respeta ambas dimensiones.
No es magia. Funciona porque cada componente tiene un rol claro y delimitado, y porque el agente orquestador sabe cuándo consultar a cada uno.
3. Auditoría de código continua e iterativa
El tercer beneficio se ve sobre todo en proyectos en los que la calidad del código importa más que la velocidad de su producción. El flujo típico es:
- Claude escribe una función.
- Claude pregunta vía MCP a ChatGPT: «¿Hay vulnerabilidades en este código? ¿Casos extremos no contemplados? ¿Mejoras de rendimiento obvias?»
- Claude consulta NotebookLM: «¿Esta función cumple la guía de estilo corporativa? ¿Hay precedentes en el código existente de la organización?»
- Claude integra los feedback de ambos y refactoriza.
- Ejecuta los tests. Si fallan, vuelve a iterar.
Esto, hecho a mano, sería un proceso de medio día por función. Hecho por el agente, son tres o cuatro minutos. La diferencia no es solo de velocidad; es que se puede hacer siempre. Cuando una revisión exhaustiva cuesta cuatro minutos, no hay excusa para saltársela. Cuando cuesta medio día, te la saltas tres de cada cuatro veces. La calidad media del código sube de manera estructural.
Lo que no es: tres advertencias importantes
Después de varias semanas con el sistema en producción para mis proyectos personales, conviene ser claro también sobre lo que el Agente de Ingeniería Total no es, para evitar las expectativas equivocadas que veo a veces en quienes empiezan a explorar esto.
No es un sustituto del ingeniero. Es un multiplicador de productividad para ingenieros. La diferencia es importante: si no sabes leer código, el agente te va a generar cosas que parecen correctas pero que pueden tener problemas sutiles que tú no detectarás. Si no entiendes la arquitectura de tu sistema, el agente puede introducir decisiones que rompan invariantes que ni siquiera sabías que existían. El humano sigue siendo responsable de las decisiones, y para serlo, tiene que entender lo que se está haciendo.
No es gratis. Los modelos de pago (Claude, GPT, Gemini) consumen tokens, y los tokens cuestan dinero. Una sesión intensa de trabajo con orquestación entre varios modelos puede consumir varios euros en una tarde. Para uso personal es absolutamente asumible pero conviene saber que el modelo de uso ilimitado de los planes flat se aplica solo al modelo principal; cuando integras varios por API, pagas por consumo.
No es infalible. Los MCPs fallan. Las APIs tienen límites de uso. Los modelos a veces alucinan. Los servidores MCP basados en Playwright son frágiles ante cambios en la interfaz web que están automatizando. Hay que tener tolerancia a fallo en el flujo de trabajo, y conviene tener mecanismos manuales de respaldo para cuando algo se cae. En mi caso, mantengo un fallback documental para cada MCP: si NotebookLM no responde, sé en qué carpeta de Drive están los PDFs originales para consultarlos directamente.
Reflexión final: la IA agéntica no es la IA del futuro, es la IA del presente
Cuando llevas un tiempo trabajando con este tipo de sistema, te das cuenta de que el paradigma de «hablar con un chatbot» se siente ya extrañamente arcaico. Es como cuando uno se acostumbra a un IDE moderno y vuelve a un editor de texto plano: técnicamente todo funciona, pero hay una sensación constante de estar haciendo a mano cosas que la máquina debería hacer por ti.

El MCP es, en este sentido, una de esas piezas de infraestructura que cambian las reglas del juego sin que se note demasiado, porque su valor no está en lo que hace directamente, sino en lo que habilita. No es sexy. No tiene una demo espectacular. Es un protocolo de mensajería entre procesos. Pero, igual que TCP/IP no es sexy y, sin embargo, sostiene todo lo demás, MCP está empezando a sostener una capa entera de la nueva forma de trabajar con IA. Y, una vez que lo tienes funcionando, no quieres volver atrás.
El Agente de Ingeniería Total no es un producto que se pueda comprar; es una composición que cada uno tiene que diseñar para su flujo de trabajo concreto. Lo que yo he construido encaja con mis proyectos (fotogrametría con drones, desarrollo de aplicaciones Android, administración de sistemas, escritura técnica y de divulgación) y se apoya en las herramientas que yo uso. El tuyo será diferente: puede que necesites un MCP de Jira en lugar de Drive, uno de Datadog en lugar de Colab, uno de tu base de datos PostgreSQL en lugar de Blender. La gracia del estándar es precisamente que da igual: una vez entiendes el patrón, lo puedes aplicar a cualquier combinación de herramientas que uses.
Si tuviera que dejar una sola recomendación a quien esté empezando, sería esta: no esperes a tener la arquitectura perfecta. Conecta un MCP, el más útil para tu caso, y úsalo durante una semana. Verás aparecer naturalmente el siguiente. Y el siguiente. El sistema crece por adición incremental, no por un diseño cerrado de arriba a abajo. Y eso es, probablemente, lo más sano que puede tener una arquitectura técnica en 2026. 🙂




1 comentario en «El Agente de Ingeniería Total»