- Nuevo servidor de virtualización – Introducción
- Nuevo servidor de virtualización – Preparación del hardware y encendido básico
- Nuevo servidor de virtualización – Uso de discos no OEM con controladora P420i
- Nuevo servidor de virtualización – Reducción de los niveles de ruido
- Nuevo servidor de virtualización – Configuración de red
- Nuevo servidor de virtualización – Instalación de ProxMox
- Nuevo servidor de virtualización – Control térmico avanzado para el verano
Hace ya un par de añitos empecé una serie sobre el nuevo servidor de virtualización que tengo instalado en casa. En su momento, uno de los artículos de la serie estuvo dedicado a la reducción de los niveles de ruido, aspecto clave para poder tener un servidor de tipo enracable en un entorno doméstico. Ese artículo trataba de cómo, gracias al proyecto iLO4 unlock, conseguí bajar el régimen de giro de los ventiladores del DL360p Gen8 del 50% al 19%, con lo que pasaba a ser viable tener un servidor de este tipo en un entorno doméstico. Dos años después, y cuando aún no hemos llegado al verano, he tenido que realizar algunas actuaciones para controlar esta velocidad de giro. Que es de lo que va este artículo.
El problema: el verano y la escalada de ventiladores
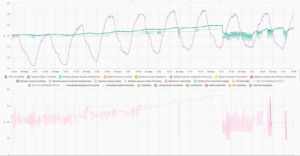
El comando mágico que me había funcionado durante dos años era fan pid lo 1200, que permite al PID interno de la iLO bajar los ventiladores hasta aproximadamente un 18%. En invierno, con temperaturas ambiente de 20°C, el servidor se mantenía silencioso sin problemas. Pero al llegar el verano, con el sensor inlet (que mide la temperatura de entrada de aire) superando los 28°C, los ventiladores empezaban a escalar de forma descontrolada, llegando a alcanzar valores de hasta el 75% en la zona derecha del servidor (la que aloja el almacenamiento y las tarjetas PCIe). Y eso suena como un Mig 21 despegando.
El problema tiene una explicación técnica interesante. El DL360p Gen8 tiene dos zonas físicas de ventilación independientes: los bloques 1-4 (izquierda, donde están las CPUs y la memoria) y los bloques 5-8 (derecha, donde están la controladora de discos y los slots PCIe). Cuando la temperatura sube, la iLO ventila ambas zonas de forma independiente, y resulta que la zona derecha es mucho más problemática: tiene componentes que generan calor de manera constante (como la controladora HD y la tarjeta de red) y que no responden al aire frío de la misma forma que las CPUs.
El servidor está ubicado en una habitación que cuenta con aire acondicionado; durante el invierno y buena parte de la primavera y el otoño el servidor puede estar perfectamente sin aire acondicionado y manteniendo niveles de giro de los ventiladores de entre el 18 y el 20%. Pero en verano (que cada vez es más largo, llega antes y se va más tarde) la cosa cambia. Me veía obligado a hacer uso del aire acondicionado para mantener los ventiladores en niveles razonables, pero a costa de tener un coste energético considerable. Y este año el «verano» se ha adelantado, teniendo ya desde el 21 de mayo temperaturas que en Santiponce alcanzaban los 35ºC.
Análisis con inteligencia artificial: Claude como copiloto
Para abordar el problema decidí utilizar un enfoque diferente al habitual: trabajar codo a codo con Claude Code para analizar el problema y aplicar soluciones. Como ya he comentado en otras ocasiones, el uso de Claude Code como asistente de ingeniería me permite ejecutar comandos SSH, leer APIs, monitorizar valores en tiempo real y proponer soluciones basándose en los datos que obtiene directamente del servidor, actuando como un ingeniero de sistemas.
Un detalle importante: durante gran parte del tiempo no tengo acceso físico al servidor. Esto implica que cualquier error que cuelgue la iLO o fije los ventiladores en un valor incorrecto que requiera intervención física me puede generar graves problemas. Esto es un condicionante clave para todo el proceso de análisis y prueba de soluciones. Implica que cada comando nuevo debía ser validado antes de ejecutarse, teniendo la absoluta certeza de que no iba a causar efectos adversos o no previstos. Y obligaba a tomar un enfoque incremental y reversible.
El proceso de análisis consistió en varias fases. En primer lugar, con mi agente de ingeniería, utilicé Gemini y NotebookLM como fuentes de análisis documental, buscando referencias específicas de uso de parámetros del parche de la iLO, modos de uso y funciones documentadas. Una vez obtenido el respaldo documental, con Claude establecí un plan de acción para implementar soluciones para la problemática, y por último usé ChatGPT como adversario en función de abogado del diablo, para buscar puntos débiles y defectos en la aproximación definida. El segundo paso fue usar Claude Code para acceder a los datos de los sensores a través de la API Redfish de la iLO, procesarlos para identificar qué sensores estaban forzando la escalada de ventiladores. Llegados a este punto, el tercer paso fue hacer una propuesta de uso de parámetros adecuados para adecuar mi script inicial de reducción de parámetros de los sensores al escenario veraniego, aplicarlos uno a uno via SSH, y monitorizar el efecto durante periodos de 30 a 60 minutos, con lecturas cada 2-5 minutos.
Entendiendo el PID de la iLO
Antes de describir la solución, merece la pena explicar cómo funciona el control de ventiladores de la iLO4 una vez desbloqueado. El sistema se basa en un controlador PID (Proporcional-Integral-Derivativo) con varios parámetros por sensor:
fan pid XX lo YYYY— El valor mínimo de PWM (Pulse Width Modulation o Modulación por Ancho de Pulsos,que permite controlar cuánta energía reciben los ventiladores) que el PID puede solicitar. Conlo 1200, los ventiladores pueden bajar hasta ~18% de su régimen de giro máximo. Existe un comando equivalente,fan pid XX hi YYYY, que permite establecer el valor máximo para el PID.fan pid XX sp YYYY— El setpoint: la temperatura objetivo para cada sensor, en décimas de grado. El PID intenta mantener el sensor por debajo de este valor.fan p X max YY— Un ceiling (techo) de PWM para cada bloque de ventiladores. Limita la velocidad máxima, independientemente de lo que el PID solicite. De igual manera, existe elfan p X min YY, que establece un suelo para la velocidad del ventilador, no permitiendo que se baje de dicho nivel.fan t XX off— Deshabilita un sensor del cálculo PID. El hardware sigue monitorizándolo para emergency shutdown, pero no influye en la velocidad de los ventiladores.
La fórmula simplificada es: output = max(clamp(PID_output, pid_lo, pid_hi), pwm_min), con el resultado final limitado por fan p max.
Un aspecto importante es que estos ajustes del PID son volátiles: se pierden cuando la iLO se reinicia o cuando el servidor arranca tras un corte de luz. Esto significa que es necesario establecer un mecanismo que los vuelva a aplicar automáticamente en cada arranque, algo que abordaré más adelante.
Iteración 1: Identificar los sensores problemáticos
El primer paso fue entender por qué la zona derecha escalaba tanto. Con el script original sólo realizaba un proceso iterativo para aplicar fan pid lo 1200 a los 53 sensores que tiene definida la iLO y tres sensores deshabilitados. Todos los demás sensores tenían sus setpoints de fábrica de iLO, que en muchos casos eran bastante conservadores.
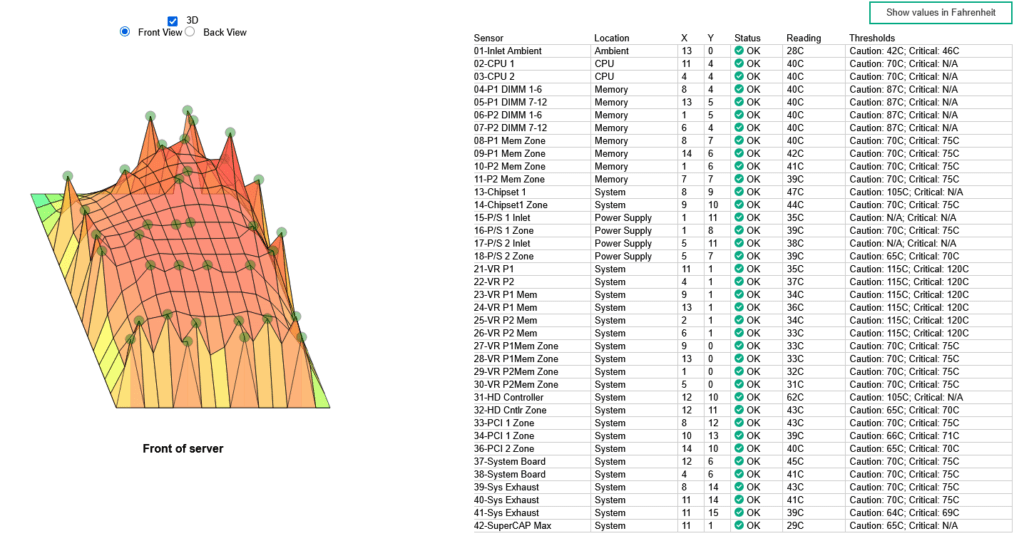
Mediante la API Redfish, extraje las temperaturas de los 42 sensores activos y las comparé con sus umbrales de precaución (la temperatura a la que iLO genera una alerta). Pude descubrir que varios sensores estaban operando a un porcentaje muy alto de su setpoint de fábrica, lo que hacía que el PID pidiera velocidades de ventilador muy altas para intentar enfriarlos, en concreto:
- 32-HD Cntlr Zone: 43°C con un SP de fábrica muy bajo — 72% de SP, principal causante de la escalada en la zona derecha.
- 36-PCI 2 Zone: 40°C, otro sensor de la zona derecha que no baja por mucho que ventiles.
- 14-Chipset1 Zone: 42°C, sensor global que puntualmente lideraba la demanda.
- 33-34 PCI 1 Zone: sensores de un slot PCI-E vacío que estaban contribuyendo al cálculo PID sin motivo.
Iteración 2: Setpoints por zona
Durante las pruebas con Claude pude determinar que los niveles a los que los sensores empezaban a demandar velocidades de giro más elevadas eran sensiblemente más bajos que los niveles de precaución declarados, por lo que los ventiladores empezaban a escalar aún estando muy lejos de los niveles de precaución formales. Es una aproximación prudente desde el punto de vista del fabricante, que prefiere quedarse muy lejos de los niveles de riesgo, pero que implica que los ventiladores se disparan aún en circunstancias donde podrían funcionar a baja velocidad.
La solución fue asignar setpoints personalizados a cada sensor, calibrados a partir de los umbrales de precaución reales de la iLO. La idea es sencilla: si el nivel de precacución de un sensor está en 65°C y la temperatura real es de 43°C, podemos poner un SP de 64°C (98% del nivel de precaución) y el PID verá que el sensor está al 67% de su objetivo, en lugar de, por ejemplo, al 90% con el SP de fábrica. El PID pedirá menos velocidad de ventilador.
Esto requirió ir sensor por sensor, consultando los valores de precaución en la web de la iLO, y calibrando cada SP entre el 85% y el 97% de dicho valor. Los sensores de la zona de almacenamiento, que son los más problemáticos porque generan calor constante que no responde al caudal de aire, recibieron SPs más agresivos (97-98% del nivel de precaución). Los de las CPUs y memoria, que sí responden bien al aire frío, mantuvieron SPs más conservadores (86-93%).
Además, deshabilité del PID un total de 13 sensores que no aportaban información útil: el sensor de inlet (no tiene sentido que el PID reaccione a la temperatura del aire de entrada), sensores de slots PCI vacíos, sensores redundantes de la zona de salida del aire, y sensores declarados pero sin uso en mi modelo de servidor, que reportaban 0°C.
Iteración 3: El ceiling con fan p max
Con los setpoints calibrados, los ventiladores ya no escalaban descontroladamente, pero seguían subiendo más de lo deseable en verano cuando el aire acondicionado dejaba de funcionar, y la temperatura ambiental empezaba a subir. Descubrí que el PID, aunque mejorado, seguía pidiendo velocidades del 50-55% en la zona derecha cuando la temperatura de la habitación subía por encima de los 27ºC.
La solución fue añadir un ceiling (techo) mediante fan p max 89 en los 8 bloques, lo que equivale a un 35% de velocidad. Este comando limita la salida máxima del PID: por mucho que el controlador quiera subir los ventiladores, no pueden pasar del 35%. Es importante entender que fan p max funciona como un techo, no como un bloqueo: si el PID quiere un 25%, los ventiladores van al 25%. Solo interviene cuando el PID pide más del 35%.
Una vez establecido el valor, estuve haciendo un proceso de monitorización bastante intensivo con Claude Code. Tenía la intuición de que un punto estable de giro podía estar en torno al 30-35% de los valores de giro incluso en verano, pero era necesario verificarlo. Así que fui bajando estos valores progresivamente desde el 41% hasta el 24%, con varias horas de monitorización, y reportes tanto por consola como por Telegram. Y el punto óptimo de estabilidad estaba en el 34%.
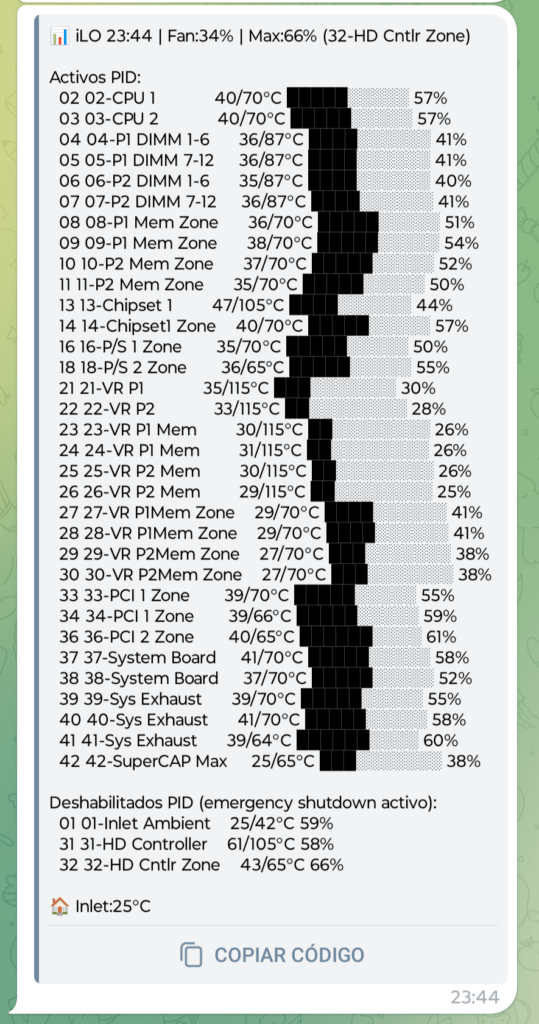
Un experimento interesante que también realicé fue quitar el ceiling temporalmente para ver qué pedía el PID realmente tras unas cuantas horas con el valor limitado al 35%. Los resultados fueron reveladores:
| Bloque | Zona | Con ceiling (35%) | Sin ceiling |
|---|---|---|---|
| 0 (Fan Block 1) | Izquierda – CPU | 34% | 56% |
| 7 (Fan Block 8) | Derecha – Storage | 34% | 94% |
Sin ceiling, la zona derecha se disparó al 94%. El ceiling es lo que mantiene este servidor silencioso en verano, pese a que los valores de los sensores nunca llegaron a escalar realmente a valores cercanos a los límites de precaución.
Con estos resultados en mente, desarrollé una nueva versión del script, con las siguientes acciones:
- Aplicación del límite inferior
fan pid lo 1200en los 52 sensores, para permitir bajar hasta el 18% del régimen de giro. - Aplicación de setpoints calibrados sensor y zona, para establecer el punto objetivo que el PID tiene que evitar alcanzar para cada uno de los sensores, más ajustados a los verdaderos valores de precaución establecidos para dichos sensores.
- Deshabilitación de 13 sensores del cálculo PID, entre sensores no utilizados, sensores redundantes o demasiado agresivos.
Iteración 4: El watchdog térmico
Tener un ceiling fijo plantea un problema evidente: ¿qué pasa si hay un pico de calor real y el servidor necesita más ventilación? Para dar respuesta a ese escenario creé un watchdog: un script en Python que corre como servicio systemd en el servidor Proxmox y monitoriza las temperaturas cada 30 segundos a través de la API Redfish, y que está destinado a permitir variar el nivel real del ceiling.
El watchdog gestiona tres estados:
- Normal:
fan p max 89(límite máximo de giro del 35%). Operación normal, silencioso. - Elevated:
fan p max 107(límite máximo de giro del 42%). Se activa cuando cualquier sensor alcanza el 90% de su setpoint. Se normaliza cuando todos bajan del 80%. - Fail-safe:
fan p max 255(límite máximo de giro del 100%). Se activa tras 5 errores consecutivos de comunicación con la iLO — elimina el ceiling completamente para que el PID nativo opere sin restricciones.
El fail-safe merece una explicación. El ceiling fan p max 89 es una restricción activa sobre el PID: si el watchdog pierde la comunicación con la iLO, ese ceiling queda fijado indefinidamente. Si durante esa desconexión hubiera un pico térmico real, el PID querría subir los ventiladores al 60-90% pero no podría porque el ceiling se lo impide. La solución es intentar eliminar el ceiling como último recurso antes de perder la conexión: el servidor pasaría a poder ventilar a toda potencia (ruidoso pero seguro) hasta que la comunicación se restablezca. Cuando el watchdog reconecta, restaura automáticamente el ceiling que corresponda según el estado térmico.
La secuencia de errores es progresiva: a los 3 errores consecutivos (1.5 minutos sin respuesta), el watchdog envía una alerta por Telegram avisando de que hay problemas de comunicación. Si la situación persiste hasta los 5 errores (2.5 minutos), se activa el fail-safe.
Comunicaciones vía Telegram
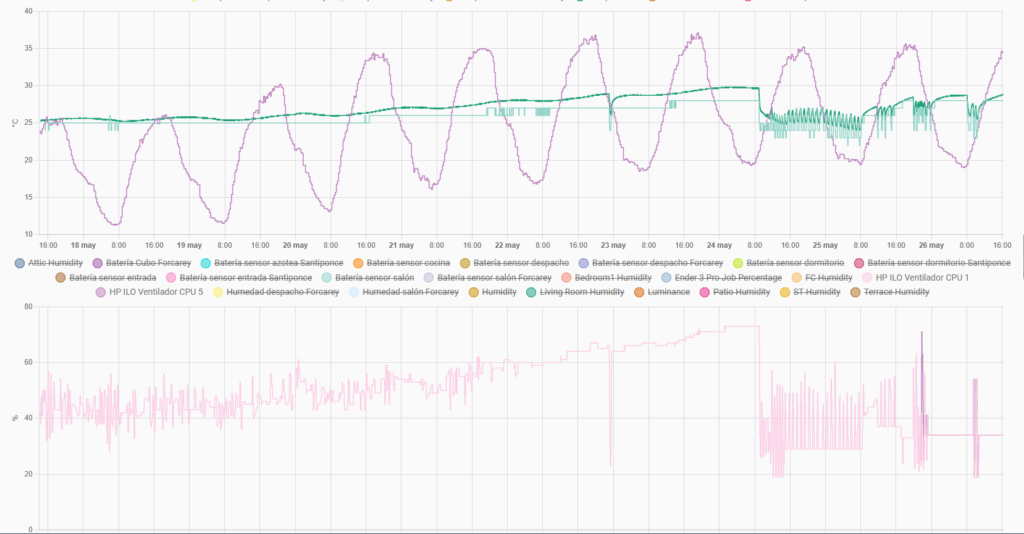
Otro de los aspectos que implementé fue el envío de mensajes vía Telegram. Dado que estaba haciendo un ciclo bastante intenso de pruebas de comandos y monitorización de los resultados, me resultaba práctico poder validar el estado del servidor, ventiladores y sensores no sólo desde la consola, sino también desde el móvil. Por ello, aprovechando que ya tenía un canal de Telegram configurado para otras alertas, definí como parte del proceso el envío de mensajes con información del estado del servidor y de posibles situaciones anómalas.
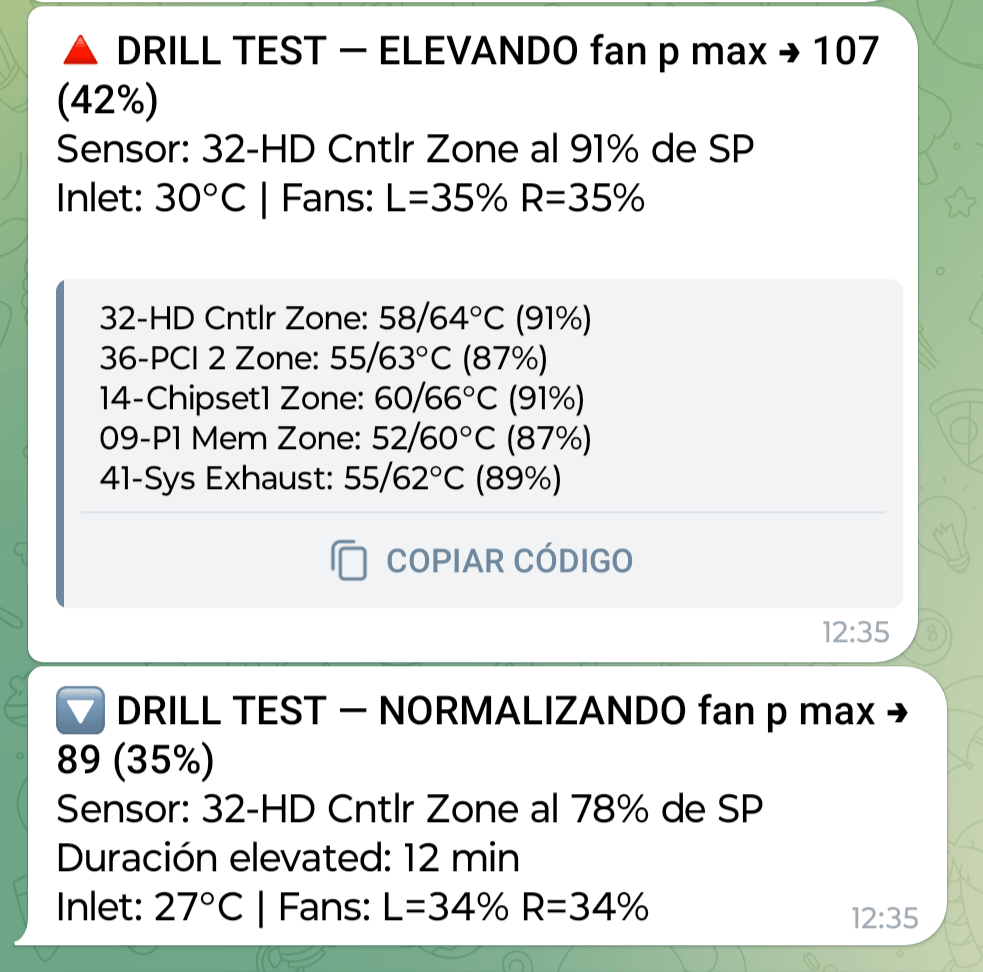
Esto implica que el watchdog envía alertas via Telegram en cada cambio de estado y genera un resumen diario a las 8:00h que incluye el tiempo acumulado en estado elevated y el número de ciclos normal↔elevated en las últimas 24 horas. Este último dato es especialmente útil para detectar el efecto rebote: si el watchdog está oscilando continuamente entre estados, es señal de que los setpoints o los umbrales necesitan ajuste.
Persistencia ante cortes de luz
Como mencioné antes, todos los ajustes del PID de la iLO son volátiles. Un corte de luz reinicia tanto el servidor como la iLO, y todos los setpoints, sensores deshabilitados y configuraciones de ceiling se pierden. El servidor, ante un reinicio del mismo o incluso un reinicio sólo de la iLO, arrancaría con la configuración de fábrica: ventiladores al 50% y el PID sin optimizar.
Para resolver esto, el script de configuración (fanspeed-dl360p-v4.sh) está registrado como servicio systemd de tipo oneshot. Esto significa que se ejecuta automáticamente en cada arranque del sistema, antes de que el watchdog comience a operar. El watchdog tiene una dependencia explícita (Requires=fanspeed-dl360p-v4.service), lo que garantiza que no arrancará hasta que la configuración del PID esté completa.
El script incluye una comprobación previa de conectividad: antes de enviar ningún comando, verifica que la iLO responde via SSH, reintentando cada 15 segundos hasta un máximo de 20 intentos (5 minutos). En un HPE ProLiant, la iLO normalmente está operativa mucho antes que el sistema operativo, pero no está de más verificarlo. Si tras 5 minutos la iLO no responde, el script aborta y el watchdog no arranca; sería una situación que requeriría intervención manual.
La secuencia de arranque completa es: servidor arranca → red disponible → fanspeed-dl360p-v4.service verifica SSH → configura PID (52 sensores con lo 1200, setpoints por zona, sensores deshabilitados) → ilo-watchdog.service arranca → aplica ceiling y comienza la monitorización.
Integración con Home Assistant: el A/C automático
La pieza final del puzzle es la automatización del aire acondicionado. Tengo Home Assistant monitorizando las velocidades de los ventiladores del servidor a través de la integración HP iLO. Cuando los ventiladores suben del 39% (lo que ocurre cuando el watchdog escala a estado elevated y sube el ceiling al 42%), una automatización enciende el aire acondicionado de la habitación.
trigger:
- platform: numeric_state
entity_id: sensor.hp_ilo_ventilador_cpu_1
above: 39
- platform: numeric_state
entity_id: sensor.hp_ilo_ventilador_cpu_5
above: 39
action:
- service: climate.turn_on
target:
entity_id: climate.aire_acondicionadoEl A/C se apaga automáticamente a los 30 minutos. En la práctica, lo que ocurre es una cadena automática: la temperatura sube → el watchdog detecta un sensor al 90% de su SP → sube el ceiling al 42% → los ventiladores suben del 39% → Home Assistant detecta la subida → enciende el A/C → la temperatura baja → el watchdog normaliza → los ventiladores vuelven al 34%. Y todo sin intervención humana.
Resultado final
Tras dos días de pruebas, análisis y ajustes incrementales, el sistema quedó estable con el siguiente comportamiento:
| Condición | Sensor Inlet | Ventiladores | Nota |
|---|---|---|---|
| Invierno | ~20°C | ~19% | PID libre, silencio total |
| Verano normal | ~27°C | ~34% | Ceiling activo, estable |
| Pico de calor | ~30°C+ | 35→42% | Watchdog + A/C automático |
| Pérdida de comunicación | — | PID libre | Fail-safe, ceiling eliminado |
Una vez implementado, realicé una una monitorización final de una hora, que confirmó estabilidad absoluta: 12 lecturas consecutivas con los ventiladores al 34%, inlet entre 27-28°C, y el sensor más caliente al 68% de su setpoint. Ni una sola anomalía.
Arquitectura del sistema
Como resultado final, el sistema ha pasado a constar de una serie de piezas que trabajan en cadena:
fanspeed-dl360p-v4.sh— Servicio systemdoneshoten Proxmox. Se ejecuta en cada arranque. Configura el PID de la iLO:fan pid lo 1200en los 52 sensores, setpoints calibrados por zona, y 13 sensores deshabilitados del cálculo PID.ilo-watchdog.py— Servicio systemd permanente en Proxmox. Arranca después de que el script de configuración termine. Monitoriza sensores via Redfish cada 30 segundos, gestiona el ceiling dinámicamente (normal/elevated/fail-safe), y alerta vía Telegram.- Automatización Home Assistant — Monitoriza la velocidad de los ventiladores via la integración HP iLO. Enciende el A/C cuando los ventiladores superan el 39%.
- Bot de Telegram — Recibe alertas en tiempo real del watchdog: cambios de estado, errores de comunicación, activación del fail-safe, y un resumen diario a las 8:00.
Este proceso, motivado por una necesidad práctica, ha sido valioso tanto por el resultado técnico como por el proceso en sí: utilizar agentes IA como copilotos para un problema que requería experimentación iterativa en hardware real, con restricción de acceso físico. Claude Code, junto con Gemini, NotebookLM y ChatGPT, ejecutaba los comandos SSH, monitorizaba los sensores, proponía cambios, los sometía a mi validación y los aplicaba. Un enfoque que habría sido mucho más tedioso, lento y arriesgado que una aproximación convencional.